Гость

Форумы
[новые:0]
/ OLAP и DWH
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Data Lake как Staging Area
[новые:0]
25 сообщений из 158, страница 6 из 7
|
|
|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
вот что происходит при update/delete с delta, просто прорефрешу инфу... 21943077 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 04.03.2020, 16:39 |
|
||






|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
churupaha churupahaа как результатом воспользоваться ? не подойдет такое в вашем случае? https://docs.microsoft.com/en-us/azure/databricks/delta/delta-faq Can I access Delta tables outside of Databricks Runtime? There are two cases to consider: external writes and external reads. External writes: Delta Lake maintains additional metadata in the form of a transaction log to enable ACID transactions and snapshot isolation for readers. In order to ensure the transaction log is updated correctly and the proper validations are performed, writes must go through Databricks Runtime. External reads: Delta tables store data encoded in an open format (Parquet), allowing other tools that understand this format to read the data. However, since other tools do not support Delta Lake’s transaction log, it is likely that they will incorrectly read stale deleted data, uncommitted data, or the partial results of failed transactions. In cases where the data is static (that is, there are no active jobs writing to the table), you can use VACUUM with a retention of ZERO HOURS to clean up any stale Parquet files that are not currently part of the table. This operation puts the Parquet files present in DBFS into a consistent state such that they can now be read by external tools. However, Delta Lake relies on stale snapshots for the following functionality, which will break when using VACUUM with zero retention allowance: Snapshot isolation for readers - Long running jobs will continue to read a consistent snapshot from the moment the jobs started, even if the table is modified concurrently. Running VACUUM with a retention less than length of these jobs can cause them to fail with a FileNotFoundException. Streaming from Delta tables - Streams read from the original files written into a table in order to ensure exactly once processing. When combined with OPTIMIZE, VACUUM with zero retention can remove these files before the stream has time to processes them, causing it to fail. For these reasons we recommend the above technique only on static data sets that must be read by external tools. + для apache spark (non databricks) https://docs.delta.io/0.4.0/delta-utility.html#enable-sql-commands-within-apache-spark ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 04.03.2020, 17:37 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
churupaha не подойдет такое в вашем случае? подойдет, но vacum убьет большую часть преимущества и по сути мало чем отличается от того, что у нас уже есть. видимо для нас сексуальной технология станет когда hive on spark научат читать напрямую. интересно, а ноутбуки типа juniper/apache zepeline, напрямую прочтут? churupaha - Для сатанистов вот тут есть (один из наших прозрел недавно) https://docs.databricks.com/applications/mlflow/index.html а так тащят с блоб стораджа трансформированное/агрегированное в виде csv/jsonline... mlflow чуть другое, это уже финальный этап, когда аналитик прошерстил весь дателейк и выудил от туда то что в модели будет использоваться. churupaha + для apache spark (non databricks) https://docs.delta.io/0.4.0/delta-utility.html#enable-sql-commands-within-apache-spark о, попробую. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.03.2020, 10:49 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
H5N1 churupaha + для apache spark (non databricks) https://docs.delta.io/0.4.0/delta-utility.html#enable-sql-commands-within-apache-spark о, попробую. а, так это стандартный параметр. не, UPDATE/DELETE не работают at org.apache.spark.sql.catalyst.parser.ParserUtils$.operationNotAllowed(ParserUtils.scala:41) это только для датабрикс облака ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 13.03.2020, 15:01 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
H5N1 H5N1 пропущено... о, попробую. а, так это стандартный параметр. не, UPDATE/DELETE не работают at org.apache.spark.sql.catalyst.parser.ParserUtils$.operationNotAllowed(ParserUtils.scala:41) это только для датабрикс облака это я кидал для vacuum (чтобы файлы напрямик потом читать можно было без side эффектов) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 14.03.2020, 22:30 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
churupaha H5N1 пропущено... а, так это стандартный параметр. не, UPDATE/DELETE не работают at org.apache.spark.sql.catalyst.parser.ParserUtils$.operationNotAllowed(ParserUtils.scala:41) это только для датабрикс облака это я кидал для vacuum (чтобы файлы напрямик потом читать можно было без side эффектов) docsApache Spark does not native support SQL commands that are specific to Delta Lake (e.g., VACUUM and DESCRIBE HISTORY). To enable such commands to be parsed, you have to configure the SparkSession to use our extension SQL parser which will parse only our SQL commands and fallback to Spark’s default parser for all other SQL commands. Here are the code snippets you should use to enable our parser. хотя вам же можно и tbl.vacuum(), но вы говорили что всё на Spark SQL запиленно (если не путаю) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 14.03.2020, 22:38 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
а ноутбуки типа juniper/apache zepeline, напрямую прочтут если ноутбуки, то люди в них читают либами всякими... delt-у с логом они конечно не прочтут правильно (без vacuum). датабрикс можно юзать из юпитера (но у нас не делают так)... https://databricks.com/blog/2019/12/03/jupyterlab-databricks-integration-bridge-local-and-remote-workflows.html https://github.com/databrickslabs/Jupyterlab-Integration#1-prerequisites ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 14.03.2020, 22:48 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Уж коли тут Databricks вовсю обсуждался, то и вопрос будет к месту. Спросил у местого Databricks разработчика : Databricks пытается вытеснить традиционный ETL, так? Вы поддерживаете кучу языков, notebooks вполне себе норм. среда для разработки. Но с т.зр. среднего BI- разработчика фигарить скрипты на python - это, если честно, back-to-the-80s подход. PowerCenter уже в 90е перешел на visual etl. Может я что-то пропустил, но планируете ли вы делать что-то в стиле классических etl-tools? В том числе и для оркестрирования всез процессов? На что получил ответ: Visual точно нет Нафиг оно кому надо Ну, мнение имеет право на жизнь :D Но с т.зр. обленившегося ETL developera переходить снова на писанину когда, когда по сути уже в 90-е был пройденный этап - зачем? Потому что миллениалам так прикольнее и у них еще руки не болят? Пытался найти нормальный app, чтоб можно было все high-level процессы не кодить как if ... then... else, а нарисовать как в PowerCenter, Datastage или, прости господи, SSIS (не к ночи будет). DataFactory ? (ок, но Микрософт пока не бесплатен) AWS Data Pipeline - убожество, "тфу на него" Щас посмотрю на StreamSets в AWS, но в прошлый раз их AMI отказался работать сразу после инсталляции, что само по себе странно. Может еще что-то есть? ЗЫ: есть некий бюджет, чтоб крутить это дело в AWS ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 21.01.2021, 17:46 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Glebanski, тут не только в самом питоне дело (всё равно больше скриптовый, а не компилируемый, соотв. ожидаемые проблемы с производительностью), DataBricks используется в контекстах [1] DataLake (прямым mount volume) который всё равно в облаках и полюбому не бесплатен [2] ML / DS контекст где SQL Server явно не настолько продвинут по функционалу (ML Services отдельный или встроенный - не настолько мощные чтобы кучу батчей в них кидать, ну может только SQL Server Big Data Cluster который не так уж и сильно взлетает у MS как продукт из-за конкуренции). Из SQL Server/Synapse можно mount делать файлам DL как external table для промежуточного ETL этапа (через Java/Polybase) - но опять-же: вопрос неопределённости схемы из-за неизвестных пока требований.. Кроме того в ETL (для Data Lake) важен не собственно сам DataBricks сколько его масштабируемый Spark Clusters именно поэтому к ETL на DataBricks идёт требование знаний Scala или хотя-бы PySpark (с его более эффективным API к Spark) а не стандартные NumPy/Pandas/Matplotlib как для PowerBI хорошо хоть mapreduce перестали требовать А так-то в DataBricks есть и DashBoards (с динамическими интерактивными параметрами) для отчётности и свой оркестратор/планировщик вообще-то да, как раньше писали - последние года 4 может создаться впечатление о шаге назад в прошлое когда сначала потребовались десятилетия чтобы перейти от работы с файлами на базы данных сo строками на миллионы/миллиарды, а теперь вдруг обратно на файловые системы, но на самом деле тут концепция немного другая т.е. данные хранятся в сыром виде, необязательно структурированные, да и какая структура понадобится пока неизвестно (поэтому для DL и schema on read подход) так что проблема в основном в том что на фоне очередного технологического взрыва - стремительно начинают меняться источники (и форма данных, да и немного - что считать данными), а разработчики рисованного ETL софта начинают сдаваться пытаясь за всем этим угнаться, в том-же SSIS я в основном использовал свой custom code на C# где SSIS был чисто для галочки как формальная среда - элементарно не хватало функционала для решения задач без хождения по граблям их модулей.. для элементарных задач конечно SSIS может и хватает, вот только таких задач в общей массе ну очень мало. Да, ADF тоже убожество (a года 3 назад вообще был ад), но свою работу вполне делает, понемногу догоняет.. п.с. для некоммерческого использования есть из бесплатных пробных (но ограниченных и тормознутых естественно) те-же kaggle или databricks community (хостится на AWS) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 21.01.2021, 18:46 |
|
||


|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Glebanski, из бесплатного вроде pentaho еще живо, но клепать визуальными штуковинами сайтики, воркфловы и etl последние лет 10 желающих нет. хотя в этом плане именно etl дольше других держались за GUI ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.01.2021, 15:53 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
H5N1 Glebanski, из бесплатного вроде pentaho еще живо, но клепать визуальными штуковинами воркфловы и etl последние лет 10 желающих нет. Мне кажется это заблуждение. У нас в НЛ вакансий на Powercenter столько же сколько на Databricks (19 vs 20) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.01.2021, 16:34 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Glebanski Мне кажется это заблуждение... (есть некоторые нюансы, но они довольно просты в освоении чтобы выносить в отдельные требования).. в вакансиях пишут или Spark/Scala или Python / Notebooks (даже можно без него напрямую указывая только опыт с необходимыми модулями {к-рых больше 100К} по сфере деятельности: автоматизация тестирования, бэк/фронт-энд, ML/DS, ETL работа с хранилищами файловыми DL или базами и пр.) С ETL/ELT кстати немного похожая история - но сам скил намного больше привязан к платформе. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.01.2021, 17:42 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Glebanski Мне кажется это заблуждение. У нас в НЛ вакансий на Powercenter столько же сколько на Databricks (19 vs 20) потому, что etl делают на spark, а запускать с плюшками датабрикса как я понимаю можно и в азуре и sql server big cluster ну и 19-20 вакансий имхо это синоним нет вакансий. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.01.2021, 18:09 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Коллеги, день добрый! Сама концепция Data Lake как Staging Area мне по нраву. Однако, обсуждение свелось к облачным решениям, а Data Lake в облаке мне кажется негуманным как по цене, там и точки зрения репликации данных в облако (временные затраты). Насколько я понимаю, заказчики предпочитают DL все-таки в периметре делать, и на бесплатных технологиях (ну, или почти-бесплатных). А уже потом: * или натравить на это кладбище данных MR / Phyton / R для получения структурированных данных и передачи данных в витрины / хранилище (в т.е. для ad-hoc анализа) * или для отработки экспериментов / теорий на всем объеме данных, но при этом опять надо знать или Phyton или R. Так что, кажется, здесь и без визуального ETL можно обойтись - значимые данные можно или MR выцепить, или все равно с Pyton / R / Mahout возится. Кстати, а есть какой-либо рекомендованный стек не для облачных инсталляций? С Уважением, Георгий. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2021, 11:40 |
|
||


|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
George Nordic, со стандартизацией имхо все плохо. миф о том что DL это неструктурированная помойка сырых данных так и продолжает жить, единственно за последние годы Databriks чуть подрос и теперь вроде чаще в связке с DL звучат термины Gold, Silver, Bronze tables. чего-то рекомендованного на своих серверах имхо нет, Cloudera объединилась с Hortonworks и продвигает свои стеки вокруг Impala. если ориентироваться на Databriks то на своих серверах самое "стандартное" видимо будет опенсорс delta.io формат и spark джобы, которые откуда-то читают и строят Gold/Silver таблицы в формате deltia.io. проблемка в том, что бесплатного хадупа теперь нет, в опенсоурс варианте delta.io вроде как нет важных оптимизаций и самое печальное, без облака Databriks эти delta.io структуры нечем показать пользователям. но в принципе схема рабочая, мы тестируем сейчас DL хранилище на delta.io (staging + MERGE в delta.io) и постройку витрин на обычных parquet файлах, которые доступны пользователям через Impala. вот только не заметно, что бы это была популярная связка и из европы выглядит, что абсолютное большинство предпочитает брать продукты в облаке и подсаживаться на вендор лок. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2021, 14:00 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
H5N1 большинство предпочитает брать продукты в облаке и подсаживаться на вендор лок. H5N1 чего-то рекомендованного на своих серверах имхо нет, Cloudera объединилась с Hortonworks и продвигает свои стеки вокруг Impala. 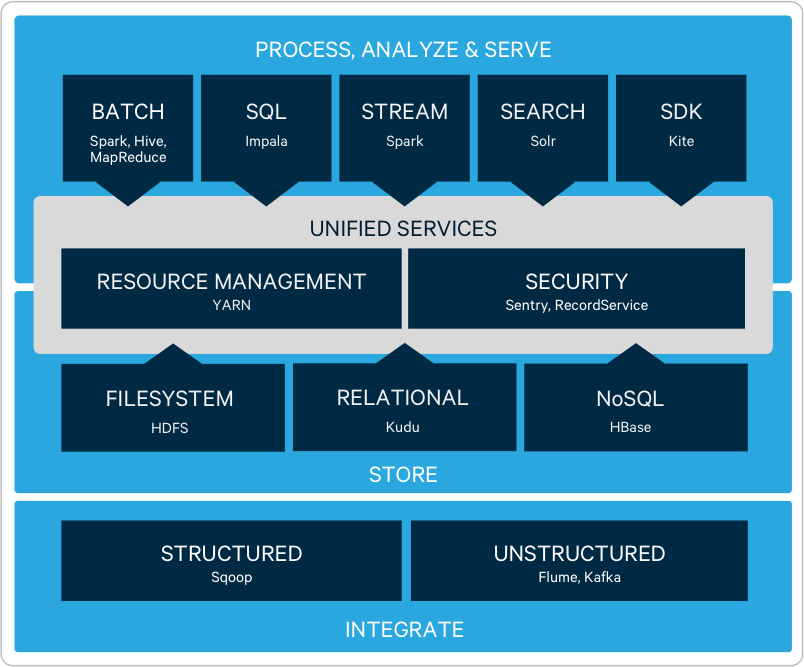 Как загрузить - понятно. А как вытаскивать для анализа, Sqoop / Kafka? В общем, мне не совсем понятно как это тот же pyton натравить, но так как стек апечевский, думаю, как-то можно. H5N1 без облака Databriks эти delta.io структуры нечем показать пользователям. но в принципе схема рабочая, мы тестируем сейчас DL хранилище на delta.io (staging + MERGE в delta.io) и постройку витрин на обычных parquet файлах, которые доступны пользователям через Impala. С Уважением, Георгий ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2021, 14:47 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
George Nordic Вот то-то. Вход - рубль, выход - нет. В принципе, не так сложно все потоки данных в облако загрузить. А вот выгрузить - об этом можно будет забыть. К тому же с подходом "тащи все, там разберемся" и "неструктурированная помойка сырых данных" - объем данных будет расти экспоненциально, вместе с расходами. тут не соглашусь. экспоненциально расти будут данные, которые на сторидже аля S3 лежат. в облачной базе, наверно данные не будут так быстро расти, т.к. нет смысла сырые и архивные данные там держать. на сколько я помню у аля S3 сториджей ценник что-то около $25/месяц за Тб. придется очень много затащить, что бы почувствовать расходы. George Nordic Как загрузить - понятно. А как вытаскивать для анализа, Sqoop / Kafka? В общем, мне не совсем понятно как это тот же pyton натравить, но так как стек апечевский, думаю, как-то можно. так это Cloudera, просто картинка их хадупа. анализировать надо там, где данные, если данные на hdfs/cloudera kudu то там, на хадупе, MR jobs или Spark запускают. с питоном я не дружу, мне кажется типичные питонисты тянут к себе обычно файлики с hdfs, у себя пытаются затянуть в pandas, данные, которые как я понимаю в память обязаны уложится. в современном ландшафте на Cloudera спарк джоб что-то там из кафки получает, очищает, гоняет по ML моделям. потом следующий в пайплайне джоб дальше строит silver, gold витрины, в том числе с результатами ML дребедени. т.е. все внутри хадуп кластера, внутри spark джобов, никуда выгружать ничего не надо. обычно спарк джобы это scala или java код, можно писать и на питоне и запускать как pySpark джоб, но говорят это заметно медленнее scala/java. хотя подозреваю запуск на кластере это при любой скорости next level на фоне обычного питон/pandas. George Nordic А через Apache Drill? не, в паркет много кто умеет, даже мой любимый продукт что такое delta.io ? это parquet файлики накиданные в единую папочку и json который указывает какие файлики от какой транзакции появились. т.е. drill, impala, vertica, все кто умеют читать паркет увидят там кашу из дублей нескольких транзакций. если инструмент не знает про delta.io то надо делать vacum что бы в фолдере остались лишь файлики с актуальными данными. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2021, 16:12 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
обычно спарк джобы это scala или java код, можно писать и на питоне и запускать как pySpark джоб, но говорят это заметно медленнее scala/java. Нашел давнишнюю статью вот http://emptypipes.org/2015/01/17/python-vs-scala-vs-spark/ Вкратце, если у тебя есть доступ к вычислительным ресурсам (а не один 386DX комп), то PySpark отлично колбасит данные, на уровне Scala. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2021, 16:39 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
статья за 15-й год, вот посвежее https://habr.com/ru/company/otus/blog/529684/ авторСегодня в Spark есть 3 API-интерфейса Scala/Java: RDD, Datasets и DataFrames (который теперь объединен с Datasets). как показывают тесты, переход на API-интерфейс Datasets может дать громадный прирост производительности за счет оптимизированного использования ЦП. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 28.01.2021, 14:36 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
H5N1, а не смотрели Apache Zeppelin под все это дело? С Уважением, Георгий ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 29.01.2021, 10:35 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
George Nordic H5N1, а не смотрели Apache Zeppelin под все это дело? пытался на cdh5, но не смог запустить на боевом кластере. тогда колудера намудрила с версиями спарка, spark2 через spark-submit2 надо было запускать + каша в путях. не осилил. на cdh6 должно взлететь, если подложить на каждую ноду либы от delta.io. я на cdh6 смотрел hive on spark, из коробки delta.io не заработала насколько помню. hive не знает про такой тип таблиц ... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 29.01.2021, 13:12 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
автор ...Сегодня в Spark есть 3 API-интерфейса Scala/Java... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 30.01.2021, 18:31 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Есть конечно и для R API в Spark ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 30.01.2021, 18:32 |
|
||

|
Data Lake как Staging Area
|
|||
|---|---|---|---|
|
#18+
Наверное из-за собственно распостранённости самого Python, т.е. не приходится учить новый язык .. естественно в PySpark есть (разумнее использовать) только DataFrame , а DataSet там нет.. (перевожу на новую страницу) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 30.01.2021, 18:35 |
|
||

25 сообщений из 158, страница 6 из 7
|
|
Форумы
[новые:0]
/ OLAP и DWH
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Data Lake как Staging Area
[новые:0]
