Гость

Форумы
[новые:0]
/ Delphi
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Как работать с очень большими масивами
[новые:0]
315 сообщений из 315, показаны все 13 страниц
|
|
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Вопрос прост и явно не раз где-нибудь обсуждался, но быстро решение гуглением не нашел. Как работать с массивом около 10 миллиардов (1е10) значений типа реал (да - все десять миллиардов разные числа формата 9.12345е26, готов на любой другой тип способный съесть подобный формат чисел). Массив задан записью: рекорд[1..3] of рекорд[1..20] of рекорд[1..60] of рекорд[1..60] of рекорд[1..163] of рекорд[1..312] с кучей побочных параметров на каждом уровне. Если сразу задать массив размером больше миллиарда - too large: exceeds 2 GB, подозреваю, что если динамически - просто вылетит на определенном этапе заполнения. Можно конечно и отказаться от данного формата работы сразу со всем объемом данных, но так неохота... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:02 |
|
||





|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
набить компьютер терабайтом памяти и использовать компилятор под x64 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:15 |
|
||



|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
или виртуализировать массив на диске (возможно, RAM-диске). Но придётся писать код ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:16 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Использовать кэширование на диске, например. Заменить record на class с индексным свойсвом, и подгружать следующие уровни по необходимости, если логика приложения это позволяет. А если необходимо чтобы всё сразу было доступно, то да - охренелиард оперативки и x64 компилятор. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Bujhtdbx, Сделать из массива БД и отдать на откуп любимому SQL серверу - не предлагать? Что с этими данными-то делать нужно? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:47 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей BujhtdbxКак работать А что подразумевается под "работать"? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:49 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
982183Андрей BujhtdbxКак работать А что подразумевается под "работать"? хотя бы нулями заполнить )))) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:49 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Bujhtdbx, 1) как заполняется массив? 2) где хранятся данные для массива? 3) почему нельзя использовать СУБД? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 10:52 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorили виртуализировать массив на диске (возможно, RAM-диске). Но придётся писать код alekcvpИспользовать кэширование на диске, например. Делаем по образу файла подкачки Windows: создаём типированный файл (f: file of tMegaRecord), небольшой массив для кеширования (buf: array of tMegaRecord) и работаем, пока на диске есть место. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 11:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
DarkMasterАндрей Bujhtdbx, Сделать из массива БД и отдать на откуп любимому SQL серверу - не предлагать? Что с этими данными-то делать нужно? Предлагать можно, но я такое не умею :(. Может как-нибудь позже. Программа пишется для себя, сам ни разу не программист. 982183Андрей BujhtdbxКак работать А что подразумевается под "работать"? В зависимости от пожеланий пользователя (то биш меня) сохранять разные относительно небольшие части этих огромных массивов в другие файлы. Выводить в виде множество разных графиков (от времени, высоты, перегрузок, прочего), в идеале выводить значения полей для сечений (это файлы полей для определенной геометрии). Объяснять подробно долго, и врят ли вам интересно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 11:15 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
GerasimenkoАндрей Bujhtdbx, 1) как заполняется массив? 2) где хранятся данные для массива? 3) почему нельзя использовать СУБД? 1. Посредством считывания двух десятков текстовых файлов по 1-2 гб каждый. 2. Если вы про исходники - как уже написал, в виде текстовых файлов, в программе пока нигде. 3. Потому, что не умею :). Долго разбираться? Freedoomdefecatorили виртуализировать массив на диске (возможно, RAM-диске). Но придётся писать код alekcvpИспользовать кэширование на диске, например. Делаем по образу файла подкачки Windows: создаём типированный файл (f: file of tMegaRecord), небольшой массив для кеширования (buf: array of tMegaRecord) и работаем, пока на диске есть место. О, первый ответ, который можно попробовать реализовать с моими знаниями. Попробую разобраться. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 11:19 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей BujhtdbxDarkMasterАндрей Bujhtdbx, Сделать из массива БД и отдать на откуп любимому SQL серверу - не предлагать? Что с этими данными-то делать нужно? Предлагать можно, но я такое не умею :(. Может как-нибудь позже. Программа пишется для себя, сам ни разу не программист. С такими данными, рано или поздно вам придется использовать СУБД. Лучше начните сейчас, сначала будет немного в гору, потом сильно полегчает. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 11:46 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей BujhtdbxDarkMasterАндрей Bujhtdbx, Сделать из массива БД и отдать на откуп любимому SQL серверу - не предлагать? Что с этими данными-то делать нужно? Предлагать можно, но я такое не умею :(. Может как-нибудь позже. Программа пишется для себя, сам ни разу не программист. 982183пропущено... А что подразумевается под "работать"? В зависимости от пожеланий пользователя (то биш меня) сохранять разные относительно небольшие части этих огромных массивов в другие файлы. Выводить в виде множество разных графиков (от времени, высоты, перегрузок, прочего), в идеале выводить значения полей для сечений (это файлы полей для определенной геометрии). Объяснять подробно долго, и врят ли вам интересно. Ну как бы СУБД именно и заточены на перелопачивание миллионов таких чисел. А сделать выборку (кусочек) от всего набора по каким-то условиям - вообще просто. В общем советую начинать смотреть в сторону СУБД. Городить свой велосипед, основанный на файлах - можно, но более трудоемко. Подумайте - в будущем вам понадобится поиск или индексы - прямая дорога к СУБД. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 11:55 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
S.G.С такими данными, рано или поздно вам придется использовать СУБД. Для таких блобов (~75GB) СУБД нафиг не нужна. Только руками, только хардкор. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
В составе TurboPower SysUtils есть готовый класс для реализации виртуальных двумерных массивов. Файл StVArr.pas Там можно создавать массивы любого размера, сколько хватит места на диске. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:33 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
DarkMaster ...Городить свой велосипед, основанный на файлах - можно, но более трудоемко. Подумайте - в будущем вам понадобится поиск или индексы - прямая дорога к СУБД. Общий объём данных (double x 10e10) составит около 75Gb. Сколько времени займёт создание БД с таким объёмом и не будет ли ограничений по количеству записей? Чтение и запись файла на диск ограничивается только производительностью HDD. Работа с файлами ничего сложного и трудоёмкого не представляет (write или blockwrite). Если копнуть чуть глубже, то все СУБД, в конечном итоге, сводятся на работу с файлами ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:36 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
982183Андрей BujhtdbxКак работать А что подразумевается под "работать"? Лопатой ворочать. Пока все 10е10 не проворочаешь, на обед не пойдешь. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:39 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
FreedoomDarkMaster ...Городить свой велосипед, основанный на файлах - можно, но более трудоемко. Подумайте - в будущем вам понадобится поиск или индексы - прямая дорога к СУБД. Общий объём данных (double x 10e10) составит около 75Gb. Сколько времени займёт создание БД с таким объёмом и не будет ли ограничений по количеству записей? Чтение и запись файла на диск ограничивается только производительностью HDD. можно положить на SSD ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:40 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
FreedoomЕсли копнуть чуть глубже, то все СУБД, в конечном итоге, сводятся на работу с файлами Если копнуть еще глубже, то не только СУБД, а почти все программы. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 12:40 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Найти сервер с не менее чем 82 Гб ОЗУ. Компилятор строго x64. Данные размещать не в стеке (его не хватит: в x32 16 МБ максимум, в x64 не знаю), а в куче (класс с вашим массивом создайте). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 13:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Эх, видимо придется разбираться, я уже о способах обработки данных думал :(, а пока даже массив загнать в программу не могу. Можно, конечно, задав исходные условия поочередно подгружать и обрабатывать файлы, но тогда каждый запрос будет как минимум ограничиваться временем чтения 40гб текстовых файлов. Ладно, либо разберусь с кешем или базами :), либо просто реализую частичную загрузку, сначала выбираю часть данных, с которыми хочу работать, работаю с ними. Если хочу другу часть - выгружаю старую, подгружаю новую. А ведь это даже не самые большие файлы полей. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 13:16 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей BujhtdbxЭх, видимо придется разбираться, я уже о способах обработки данных думал :(, а пока даже массив загнать в программу не могу. Можно, конечно, задав исходные условия поочередно подгружать и обрабатывать файлы, но тогда каждый запрос будет как минимум ограничиваться временем чтения 40гб текстовых файлов. Ладно, либо разберусь с кешем или базами :), либо просто реализую частичную загрузку, сначала выбираю часть данных, с которыми хочу работать, работаю с ними. Если хочу другу часть - выгружаю старую, подгружаю новую. А ведь это даже не самые большие файлы полей. а может быть, стоит задуматься о структурах данных более тщательно ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:05 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
01.11.2017 14:05, defecator пишет: > а может быть, стоит задуматься о структурах данных более тщательно +100500! а ТС-у можно рекомендовать ознакомиться с книжкой Н.Вирта "Алгоритмы + структуры данных = программы" Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecator, +1. Очень даже возможно, что человеку не нужен этот гиганский массив. Либо наоборот - тут и петабайтных размеров мало будет. Мы не знаем, о какой предметной области идет речь, насколько ТС в ней компетентен,насколько адекватна выбранная модель отображения предметной области в компьютеризуемую задачу. Например, если знаешь, что такой-то параметр на заданном участке меняется линейно, вовсе нет надобности хранить значение этого параметра для каждого кванта времени. Я понимаю, что был задан конкретный вопрос, не связанный с предметной областью. Однако, учитывая большие объемы, важно принять правильное решение. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:19 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorАндрей BujhtdbxЭх, видимо придется разбираться, я уже о способах обработки данных думал :(, а пока даже массив загнать в программу не могу. Можно, конечно, задав исходные условия поочередно подгружать и обрабатывать файлы, но тогда каждый запрос будет как минимум ограничиваться временем чтения 40гб текстовых файлов. Ладно, либо разберусь с кешем или базами :), либо просто реализую частичную загрузку, сначала выбираю часть данных, с которыми хочу работать, работаю с ними. Если хочу другу часть - выгружаю старую, подгружаю новую. А ведь это даже не самые большие файлы полей. а может быть, стоит задуматься о структурах данных более тщательно Эти данные я получаю уже в готовом виде, да и ничего особенного тут нет, обычные поля (нейтронные, температурные) в пространстве и времени, просто поля в геометрии задаются исходя из особенностей конструкции. При том сетка по высоте и времени далеко не плотная. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
01.11.2017 14:20, Андрей Игоревич пишет: > Эти данные я получаю уже в готовом виде, да и ничего особенного тут нет, обычные поля (нейтронные, температурные) > в пространстве и времени, просто поля в геометрии задаются исходя из особенностей > конструкции. При том сетка по высоте и времени далеко не плотная. Андрей, а почему не Fortran? Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичdefecatorпропущено... а может быть, стоит задуматься о структурах данных более тщательно Эти данные я получаю уже в готовом виде, да и ничего особенного тут нет, обычные поля (нейтронные, температурные) в пространстве и времени, просто поля в геометрии задаются исходя из особенностей конструкции. При том сетка по высоте и времени далеко не плотная.привет, опять пытаешь диск. Надо задачу определить которую хочешь решить, БД ИМХО не спасёт. для начала может исходные текстовки в бинарные перевести, что бы диск не терроризировать, заодно структуру и объём узнаешь ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:44 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Мимопроходящий01.11.2017 14:20, Андрей Игоревич пишет: > Эти данные я получаю уже в готовом виде, да и ничего особенного тут нет, обычные поля (нейтронные, температурные) > в пространстве и времени, просто поля в геометрии задаются исходя из особенностей > конструкции. При том сетка по высоте и времени далеко не плотная. Андрей, а почему не Fortran? А почему Фортран? :). А вообще потому что не умею :). И не очень авторитетные источники утверждают, что делфи не сильно то и медленней фортрана (сам не проверял). С высокой долей вероятности эти файлы получены в результате расчетов программах на фортране). Как там с фортраном в части интерфейса? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 14:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
kealon(Ruslan)Андрей Игоревичпропущено... Эти данные я получаю уже в готовом виде, да и ничего особенного тут нет, обычные поля (нейтронные, температурные) в пространстве и времени, просто поля в геометрии задаются исходя из особенностей конструкции. При том сетка по высоте и времени далеко не плотная.привет, опять пытаешь диск. Надо задачу определить которую хочешь решить, БД ИМХО не спасёт. для начала может исходные текстовки в бинарные перевести, что бы диск не терроризировать, заодно структуру и объём узнаешь Ну структуру и объем я сразу знаю, там все относительно хорошо структурировано (каждый уровень обозначен и подписан понятным способом). А в бинарники я первым делом и планировал загнать, просто хотел сразу всё, но видать не судьба, придется кусками. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 15:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
01.11.2017 14:58, Андрей Игоревич пишет: > Как там с фортраном в части интерфейса? ты имеешь в виду GUI? глянь Compaq Visual Fortran и Compaq Array Visualizer. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 15:07 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 15:34 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arm79, вряд ли тут разреженные массивы пригодятся, у него непрерывный плотный поток данных во всем диапазоне координат, которые заранее неизвестно как использовать. Тут, возможно, типизированные файлы использовать следует. Даже "быстрые" субд типа ключ-значение могут оказаться слишком медленными. Опять, мы не знаем, для чего человеку это нужно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 15:42 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Тут принято на каждый вопрос свою тему или можно продолжать в старой? Просто возникла следующая сложность. В основной программе где уже много всего текстовые файлы считываются в 10-100 раз медленней, чем в другой программе, ну или просто в чистой, только со считыванием. Для чистоты эксперимента код в чистой и основной программе упростил до нескольких строк, ничего нигде при работе цикла не подключается. (ну для себя всякие таймеры подключал для удобства, на суть они не виляют). Основная программа прогоняет исходный текстовый файл в 3 гб (кстати 1-2 гб они только заархивированные были) за дикие 15-30 минут, чистая программа - за 1 минуту 12 секунд в среднем. Есть и другая программа где я уже обрабатывал куски этих файлов (и ещё не столкнулся с проблемами огромных массивов), там тоже всё шустро работает. По какой причине, абсолютно один и тот же код выполняется настолько разное время? Где искать проблему? Модули подключил везде одни и те же. Отключение мегамасива не влияет. procedure TForm1.Button1Click(Sender: TObject); var tf:TextFile; FS,PoF,PZ,tmp:integer; st:string; begin OpenDialog1.Execute; Reset (TF,OpenDialog1.FileName); if FileExists(OpenDialog1.FileName) then while (not EOF (TF)) do Readln(TF,St); closefile (TF); end; ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:14 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичТут принято на каждый вопрос свою тему или можно продолжать в старой? в новой чччДArm79, вряд ли тут разреженные массивы пригодятся, у него непрерывный плотный поток данных во всем диапазоне координат, если так, то без файлов никуда, нужен кластеризованный индекс типа B+. Собственно - это и есть СУБД. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:23 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичprocedure TForm1.Button1Click(Sender: TObject); var tf:TextFile; FS,PoF,PZ,tmp:integer; st:string; begin OpenDialog1.Execute; Reset (TF,OpenDialog1.FileName); if FileExists(OpenDialog1.FileName) then while (not EOF (TF)) do Readln(TF,St); closefile (TF); end;Не делай так, если времени жалко. Уж лучше TStrings.LoadFromFile ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerАндрей Игоревичprocedure TForm1.Button1Click(Sender: TObject); var tf:TextFile; FS,PoF,PZ,tmp:integer; st:string; begin OpenDialog1.Execute; Reset (TF,OpenDialog1.FileName); if FileExists(OpenDialog1.FileName) then while (not EOF (TF)) do Readln(TF,St); closefile (TF); end;Не делай так, если времени жалко. Уж лучше TStrings.LoadFromFile у него файлы по 10-40 гигабайт ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:34 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Посмотри на System.SetTextBuf() функцию. С ней я думаю пошустрее будет :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:37 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичПо какой причине, абсолютно один и тот же код выполняется настолько разное время? Где искать проблему? Запускаешь из среды и ту и другую? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:44 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerАндрей Игоревичprocedure TForm1.Button1Click(Sender: TObject); var tf:TextFile; FS,PoF,PZ,tmp:integer; st:string; begin OpenDialog1.Execute; Reset (TF,OpenDialog1.FileName); if FileExists(OpenDialog1.FileName) then while (not EOF (TF)) do Readln(TF,St); closefile (TF); end;Не делай так, если времени жалко. Уж лучше TStrings.LoadFromFile И мозгов побольше, чтобы эти Strings вместить ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:45 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerАндрей Игоревичprocedure TForm1.Button1Click(Sender: TObject); var tf:TextFile; FS,PoF,PZ,tmp:integer; st:string; begin OpenDialog1.Execute; Reset (TF,OpenDialog1.FileName); if FileExists(OpenDialog1.FileName) then while (not EOF (TF)) do Readln(TF,St); closefile (TF); end;Не делай так, если времени жалко. Уж лучше TStrings.LoadFromFile Код: pascal 1. 2. 3. 4. для данных 3хгиговых файлов выдает зиро (0), для остальных небольших текстовых файлов - все нормально, подозреваю что стринглист такие файлы не осилит defecatorwhite_niggerпропущено... Не делай так, если времени жалко. Уж лучше TStrings.LoadFromFile у него файлы по 10-40 гигабайт Ну файлы по 2-3 гб, просто их до 20 штук. (Один файл - один год эксплуатации) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:54 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyАндрей ИгоревичПо какой причине, абсолютно один и тот же код выполняется настолько разное время? Где искать проблему? Запускаешь из среды и ту и другую? Да, из одной и той же среды, в обеих случая скорость явно упирается в процессор (1 ядро на максимум занимают), многозадачность пока не уметь. Если успею даже с 10.1 попробую запустить, если она скушает. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 16:56 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичДа, из одной и той же среды Под средой я имею ввиду IDE. То есть и "быстрая" программа запускается из-под IDE и "медленная"? Если нет, но вероятно влияние отладчика. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Для очень хорошей скорости работы с текстом используй библиотеку CachedTexts А для произвольных данных - CachedBuffers ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:08 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyАндрей ИгоревичДа, из одной и той же среды Под средой я имею ввиду IDE. То есть и "быстрая" программа запускается из-под IDE и "медленная"? Если нет, но вероятно влияние отладчика. Не совсем понимаю, что тут подразумевается под IDE, но запускаю два раза программу с логичным именем Delphi 7 (которая и язык и среда, пароход), в одной компилирую и тестирую одну программу, в другой - другую. Запускаю не одновременно. Сейчас запустил и скомлировал в Delphi 10.1 (уж не знаю как там теперь называют используемый язык, паскаль, делфе, делфи 7 или делфи 10), считало файл за 1 минуту, и правда - виноват компилятор. Хорошо, что не делал отдельную тему на сей глупый вопрос. П.С. Удивительно, что в делфи 10 Reset без Assignfile не работает... П.С. 2 По причине конца рабочего дня и потери доступа к компьютеру с программой отвечать на сообщения по сути до завтрашнего утра более не могу. :) Прошу не серчать. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:13 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Андрей ИгоревичЗапускаю не одновременно. Запускаешь как? Просто F9, или может из командной строки/ярлыком? В общем ладно, если запускаешь одинаково и на одних данных, то дело не в отладчике. Андрей Игоревичи правда - виноват компилятор Нет, "виноват", скорее всего, менеджер памяти. Андрей Игоревичуж не знаю как там теперь называют используемый язык Object Pascal. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:22 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, интересная задача. но, если покажете сообществу образцы, примерные форматы, которые грузите, и расскажите, что хотите с ними делать - возможно советы будут более предметными. С уважением ........ ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, авторП.С. Удивительно, что в делфи 10 Reset без Assignfile не работает... Нужно же как-то узнать что (какой именно файл) сбрасывать? :) Интересно попробовать загрузить в TStringList целый файл сразу. Я не пробовал, не знаю, чем закончится. Скорее всего - ничем хорошим. В 64х, само собой. По хорошему - прикрутить какую-нибудь базу. Пусть бы она и считала. Может даже и без Delphi вообще справится. Результаты только в гуй вывести. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:40 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
75 гиг - не смертельно. На SSD, и данные, и базу - должно довольно шустро влиться, я думаю. Ну а дальше можно делать что угодно и как нужно. Не очень сложно, хотя, если совсем с нуля, то могут быть некоторые сложности. Готовые примеры лучше всего смотреть. Их вагон и тележка в сети. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 17:46 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
авторВ зависимости от пожеланий пользователя (то биш меня) сохранять разные относительно небольшие части этих огромных массивов в другие файлы. тут скорее всего надо сохранять по мере чтения, тогда память не перегрузится. причем, если и вход и выход - текстовые, не факт что паскаль из делфи - самый органичный язык для такой обработки. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 18:16 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
и, если читать нужно много раз, для каждого файла данных можно создавать индекс, чтобы позиционироваться быстрее, если нужно не начало. Тогда при повторных чтениях не придется ворочать файл построчно. И, конечно имеет смысл перегнать в бинарную форму, чтобы при новых чтениях не приходилось разбирать числа снова и снова, да и позиционироваться в бинарных файлах куда как проще, чем в текстовых..... размер блока*количество = мы на месте. бинарный файл, возможно ужмется в размере, и можно станет использовать механизм http://xaker.name/threads/25694/ Memory Mapped Files. Или каждый файл данных разбивать на бинарные так, чтобы влезал. Тогда по моему станет нормально решать поставленные задачи. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 18:29 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Ещё с 80-х годов прошлого столетия существуют хитрые алгоритмы, которые превращают любой массив чисел в степенные функции. Я уже не помню подробностей, но в то время использовал их для массивов (довольно объемных) нормативов времени и режимов резанья (машиностоительная технологическая САПР). Точность получается вполне удовлетворительная. Если задача допускает некоторое снижение точности, есть смысл над этим подумать... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 18:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SQLite InMemory и не выдумывайте ничего! ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.11.2017, 22:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Уважаемый авторSQLite InMemory и не выдумывайте ничего! авторКак работать с массивом около 10 миллиардов (1е10) значений типа реал (да - все десять миллиардов разные числа формата 9.12345е26, готов на любой другой тип способный съесть подобный формат чисел). Массив задан записью: рекорд[1..3] of рекорд[1..20] of рекорд[1..60] of рекорд[1..60] of рекорд[1..163] of рекорд[1..312] с кучей побочных параметров на каждом уровне. Уважаемый автор , а как Вы предлагаете засовывать туда описанную выше стр-ру данных, и сколько места ин мемори она предположительно займет, чтобы все значения были легкодоступны? мне не кажется очевидным, что все будет легко и красиво. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 09:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir BaskakovАндрей Игоревич, интересная задача. но, если покажете сообществу образцы, примерные форматы, которые грузите, и расскажите, что хотите с ними делать - возможно советы будут более предметными. С уважением ........ Ну уж не знаю зачем оно вам надо, но могу и показать, да рассказать, не секретно. Все просто текстовые файлы с распределением полей по 3х мерной геометрии во времени. Если более конкретно: нейтронные поля в активной зоне реактора. Координаты точек поля задаются на основании геометрии ТВС и твэлов. (в активной зоне 163 ТВС в каждой по 312 твэлов, 5-60 отсечек по высоте и 50-60 отсечек по времени для каждого года эксплуатации). Содержание файла представляет тысячи и тысячи блоков формата FLUX001001000000 E>=0.1 2.68237E+13,2.86991E+13,2.86198E+13,2.66761E+13,2.49279E+13,2.50176E+13,2.68420E+13,3.05655E+13,3.05324E+13,3.03947E+13,2.84124E+13,2.64006E+13,2.46938E+13,2.30162E+13,2.31666E+13,2.32262E+13, 2.49536E+13,2.67552E+13,2.86337E+13,3.25414E+13,3.10929E+13,3.24436E+13,3.22929E+13,2.88898E+13,2.81980E+13,2.61667E+13,2.33781E+13,2.27809E+13,2.12300E+13,2.04919E+13,2.15459E+13,2.15688E+13, 2.21704E+13,2.48872E+13,2.66729E+13,2.73125E+13,3.05145E+13,3.46456E+13,3.45951E+13,3.45530E+13,3.45253E+13,3.43325E+13,3.21060E+13,3.00110E+13,2.79882E+13,2.59154E+13,2.42194E+13,2.25523E+13, 2.01067E+13,1.95701E+13,1.98043E+13,1.99377E+13,2.00060E+13,1.99277E+13,2.14984E+13,2.31055E+13,2.48309E+13,2.65389E+13,2.84739E+13,3.04549E+13,3.25724E+13,3.52034E+13,3.68067E+13,3.67907E+13, 3.67284E+13,3.65886E+13,3.48230E+13,3.41310E+13,3.18976E+13,2.97774E+13,2.76532E+13,2.44813E+13,2.39554E+13,2.23163E+13,2.07708E+13,1.93456E+13,1.72183E+13,1.82258E+13,1.83614E+13,1.84365E+13, 1.84456E+13,1.75525E+13,1.98200E+13,2.13562E+13,2.29481E+13,2.46509E+13,2.52253E+13,2.83422E+13,3.03901E+13,3.24575E+13,3.46169E+13,3.90867E+13,3.91052E+13,3.90987E+13,3.73402E+13,3.89493E+13, 3.87928E+13,3.86078E+13,3.62162E+13,3.38722E+13,3.02584E+13,2.94980E+13,2.73463E+13,2.52736E+13,2.36316E+13,2.20176E+13,1.96025E+13,1.91156E+13,1.77763E+13,1.65105E+13,1.67404E+13,1.68899E+13, 1.62218E+13,1.70111E+13,1.69815E+13,1.68636E+13,1.82307E+13,1.96771E+13,2.02358E+13,2.27560E+13,2.44633E+13,2.62106E+13,2.82126E+13,3.02883E+13,3.09524E+13,3.45167E+13,3.67777E+13,4.15157E+13, 4.15969E+13,4.16099E+13,4.14825E+13,4.14053E+13,4.13732E+13,4.11963E+13,4.09461E+13,3.84528E+13,3.60285E+13,3.36135E+13,3.13728E+13,2.92179E+13,2.70397E+13,2.48679E+13,2.32392E+13,2.16734E+13, 2.01535E+13,1.87683E+13,1.74691E+13,1.62100E+13,1.49917E+13,1.52829E+13,1.54807E+13,1.55843E+13,1.56367E+13,1.56394E+13,1.55474E+13,1.53645E+13,1.66778E+13,1.80389E+13,1.94408E+13,2.09285E+13, 2.25583E+13,2.42422E+13,2.60004E+13,2.81000E+13,3.02006E+13,3.22725E+13,3.44328E+13,3.67666E+13,3.91060E+13,4.28304E+13,4.40048E+13,4.41044E+13,4.41074E+13,4.40447E+13,4.39467E+13,4.37809E+13, 4.35156E+13,4.21841E+13,4.06179E+13,3.81396E+13,3.57110E+13,3.33527E+13,3.10685E+13,2.88147E+13,2.65568E+13,2.37280E+13,2.26794E+13,2.11481E+13,1.96849E+13,1.83040E+13,1.70080E+13,1.57766E+13, 1.45919E+13,1.31408E+13,1.37974E+13,1.40489E+13,1.42083E+13,1.42898E+13,1.43025E+13,1.42385E+13,1.40854E+13,1.35270E+13,1.50833E+13,1.63714E+13,1.77105E+13,1.91180E+13,2.06175E+13,2.22092E+13, 2.38799E+13,2.50523E+13,2.78301E+13,3.00066E+13,3.21741E+13,3.43694E+13,3.66380E+13,3.89760E+13,4.13643E+13,4.60353E+13,4.63324E+13,4.65261E+13,4.66170E+13,4.66158E+13,4.65335E+13,4.63701E+13, 4.61140E+13,4.57537E+13,4.52854E+13,4.27000E+13,4.01712E+13,3.76943E+13,3.52738E+13,3.29078E+13,3.05799E+13,2.82636E+13,2.59296E+13,2.35486E+13,2.19557E+13,2.04437E+13,1.90124E+13,1.76621E+13, 1.63905E+13,1.51908E+13,1.40526E+13,1.29627E+13,1.19076E+13,1.23127E+13,1.26093E+13,1.28112E+13,1.29299E+13,1.29721E+13,1.29384E+13,1.28240E+13,1.26206E+13,1.23216E+13,1.34815E+13,1.46825E+13, 1.59339E+13,1.72496E+13,1.86447E+13,2.01307E+13,2.17115E+13,2.33845E+13,2.51477E+13,2.74406E+13,2.96861E+13,3.19095E+13,3.41403E+13,3.64071E+13,3.87279E+13,4.11060E+13,4.35391E+13,4.81290E+13, 4.85582E+13,4.88451E+13,4.90257E+13,4.90995E+13,4.90669E+13,4.89297E+13,4.86878E+13,4.83410E+13,4.78885E+13,4.72892E+13,4.46676E+13,4.20919E+13,3.95690E+13,3.70999E+13,3.46800E+13,3.22970E+13, 2.99338E+13,2.75682E+13,2.51718E+13,2.26879E+13,2.10583E+13,1.95454E+13,1.81394E+13,1.68257E+13,1.55909E+13,1.44288E+13,1.33378E+13,1.23145E+13,1.13489E+13,1.04244E+13,1.08517E+13,1.11777E+13, 1.14136E+13,1.15666E+13,1.16421E+13,1.16424E+13,1.15665E+13,1.14109E+13,1.11725E+13,1.08502E+13,1.18961E+13,1.29907E+13,1.41400E+13,1.53510E+13,1.66356E+13,1.80080E+13,1.94807E+13,2.10624E+13, 2.27579E+13,2.45731E+13,2.69520E+13,2.92488E+13,3.15122E+13,3.37679E+13,3.60403E+13,3.83497E+13,4.07090E+13,4.31242E+13,4.55988E+13, E>=1.0 1.16438E+13,1.24622E+13,1.24296E+13,1.15824E+13,1.08178E+13,1.08535E+13,1.16495E+13,1.32776E+13,1.32643E+13,1.32068E+13,1.23410E+13,1.14654E+13,1.07190E+13,9.98433E+12,1.00465E+13,1.00667E+13, 1.08229E+13,1.16081E+13,1.24330E+13,1.41404E+13,1.33272E+13,1.41004E+13,1.40357E+13,1.23825E+13,1.22470E+13,1.13609E+13,1.00094E+13,9.88160E+12,9.19839E+12,8.75814E+12,9.32950E+12,9.33155E+12, 9.47314E+12,1.07871E+13,1.15654E+13,1.16939E+13,1.32552E+13,1.50549E+13,1.50377E+13,1.50200E+13,1.50056E+13,1.49204E+13,1.39528E+13,1.30372E+13,1.21519E+13,1.12436E+13,1.05050E+13,9.77717E+12, 8.57998E+12,8.46136E+12,8.56385E+12,8.61915E+12,8.64292E+12,8.60016E+12,9.29057E+12,9.99626E+12,1.07501E+13,1.14970E+13,1.23529E+13,1.32249E+13,1.41497E+13,1.50891E+13,1.59985E+13,1.59916E+13, 1.59640E+13,1.59033E+13,1.49284E+13,1.48303E+13,1.38577E+13,1.29295E+13,1.20003E+13,1.04704E+13,1.03779E+13,9.66462E+12,8.98646E+12,8.35664E+12,7.32190E+12,7.85971E+12,7.91919E+12,7.94762E+12, 7.94246E+12,7.44519E+12,8.53870E+12,9.21377E+12,9.91223E+12,1.06553E+13,1.07649E+13,1.22858E+13,1.31877E+13,1.40961E+13,1.50391E+13,1.69881E+13,1.69985E+13,1.69963E+13,1.60095E+13,1.69307E+13, 1.68618E+13,1.67784E+13,1.57360E+13,1.47161E+13,1.29644E+13,1.28003E+13,1.18559E+13,1.09376E+13,1.02206E+13,9.51824E+12,8.35441E+12,8.24262E+12,7.64831E+12,7.07941E+12,7.18749E+12,7.25604E+12, 6.87686E+12,7.30055E+12,7.27548E+12,7.20676E+12,7.81569E+12,8.45337E+12,8.59129E+12,9.80569E+12,1.05511E+13,1.13175E+13,1.22147E+13,1.31334E+13,1.32527E+13,1.49939E+13,1.59801E+13,1.80431E+13, 1.80796E+13,1.80867E+13,1.80352E+13,1.80012E+13,1.79826E+13,1.79032E+13,1.77918E+13,1.67058E+13,1.56499E+13,1.45988E+13,1.36168E+13,1.26692E+13,1.17079E+13,1.07426E+13,1.00298E+13,9.34563E+12, 8.68122E+12,8.07174E+12,7.49724E+12,6.93501E+12,6.38406E+12,6.52144E+12,6.61286E+12,6.65836E+12,6.67720E+12,6.66953E+12,6.61488E+12,6.51351E+12,7.10060E+12,7.70314E+12,8.32019E+12,8.97373E+12, 9.68684E+12,1.04253E+13,1.11992E+13,1.21460E+13,1.30830E+13,1.40014E+13,1.49528E+13,1.59715E+13,1.69924E+13,1.85051E+13,1.91319E+13,1.91749E+13,1.91771E+13,1.91503E+13,1.91061E+13,1.90320E+13, 1.89152E+13,1.82193E+13,1.76499E+13,1.65692E+13,1.55099E+13,1.44792E+13,1.34772E+13,1.24847E+13,1.14847E+13,1.01622E+13,9.76198E+12,9.09025E+12,8.44915E+12,7.84333E+12,7.27221E+12,6.72532E+12, 6.19272E+12,5.50210E+12,5.83533E+12,5.95250E+12,6.02446E+12,6.05820E+12,6.05748E+12,6.01833E+12,5.93371E+12,5.62962E+12,6.35930E+12,6.93110E+12,7.52083E+12,8.13844E+12,8.79558E+12,9.49433E+12, 1.02309E+13,1.06896E+13,1.20094E+13,1.29863E+13,1.39502E+13,1.49195E+13,1.59151E+13,1.69376E+13,1.79806E+13,2.00380E+13,2.01591E+13,2.02399E+13,2.02785E+13,2.02779E+13,2.02414E+13,2.01690E+13, 2.00568E+13,1.99008E+13,1.97012E+13,1.85671E+13,1.74613E+13,1.63789E+13,1.53206E+13,1.42841E+13,1.32608E+13,1.22376E+13,1.11988E+13,1.01275E+13,9.41829E+12,8.75008E+12,8.12023E+12,7.52755E+12, 6.96906E+12,6.43945E+12,5.93148E+12,5.43637E+12,4.94585E+12,5.13960E+12,5.27891E+12,5.37122E+12,5.42299E+12,5.43751E+12,5.41471E+12,5.35125E+12,5.24103E+12,5.07813E+12,5.60417E+12,6.13895E+12, 6.68986E+12,7.26603E+12,7.87636E+12,8.52824E+12,9.22590E+12,9.97062E+12,1.07649E+13,1.18203E+13,1.28366E+13,1.38307E+13,1.48196E+13,1.58182E+13,1.68365E+13,1.78778E+13,1.89429E+13,2.09706E+13, 2.11467E+13,2.12659E+13,2.13426E+13,2.13745E+13,2.13599E+13,2.12989E+13,2.11920E+13,2.10404E+13,2.08453E+13,2.05890E+13,1.94397E+13,1.83109E+13,1.72062E+13,1.61255E+13,1.50653E+13,1.40188E+13, 1.29767E+13,1.19271E+13,1.08533E+13,9.72385E+12,8.98983E+12,8.31321E+12,7.68999E+12,7.11180E+12,6.57076E+12,6.06136E+12,5.57937E+12,5.11945E+12,4.67400E+12,4.23267E+12,4.44099E+12,4.59536E+12, 4.70401E+12,4.77211E+12,4.80294E+12,4.79755E+12,4.75477E+12,4.67137E+12,4.54285E+12,4.36327E+12,4.84288E+12,5.33132E+12,5.83610E+12,6.36399E+12,6.92315E+12,7.52238E+12,8.17020E+12,8.87425E+12, 9.64069E+12,1.04732E+13,1.15854E+13,1.26362E+13,1.36557E+13,1.46609E+13,1.56661E+13,1.66827E+13,1.77183E+13,1.87773E+13,1.98622E+13, Где первая строка есть указатель времени, координаты и высоты. вторая и ещё одна где-то по середине - указатель энергии нейтронов (тепловые, быстрые), цифры - значения поля в конкретном твэле для указанных выше времени, энергии, ТВС и высоты. Так же есть небольшой файл перегрузок. Сразу говорю, я не программист, делаю данную программу для упрощения некоторых операций в работе, исключительно по собственной инициативе :). Для примера что мне надо: Поиск ТВС, твэла, участка твэла с наибольшим флюэнсом (накопленной радиацией), по сути обычный интеграл(сумма) для конкретного участка от времени. Всевозможные зависимости плотностей потока от высоты, времени по каналу, времени для конкретной ТВС, по сечению. Поиск всяких максимумов и минимумов, перекосов. Естественно для этого уже есть созданные программы, но своя удобней :). В принципе можно не подгружать всю геометрию, то есть "укрупнить сетку", так я сейчас и делаю. Vladimir BaskakovавторВ зависимости от пожеланий пользователя (то биш меня) сохранять разные относительно небольшие части этих огромных массивов в другие файлы. тут скорее всего надо сохранять по мере чтения, тогда память не перегрузится. причем, если и вход и выход - текстовые, не факт что паскаль из делфи - самый органичный язык для такой обработки. Можно, но уж очень медленно, а про делфипаскаль - чему умею, тем и делаю :). d7iЕщё с 80-х годов прошлого столетия существуют хитрые алгоритмы, которые превращают любой массив чисел в степенные функции. Я уже не помню подробностей, но в то время использовал их для массивов (довольно объемных) нормативов времени и режимов резанья (машиностоительная технологическая САПР). Точность получается вполне удовлетворительная. Если задача допускает некоторое снижение точности, есть смысл над этим подумать... Аппроксимация, конечно, дичайше ужмет данные массивы (что логично, так как они в основном и есть решения множества степенных функций + итерации), но очень уж для меня это усложнит задачу. Может как-нибудь потом). А то так вообще приду к тому, что проще станет исходную расчетную программу написать. В общем всем спасибо, советов тьма, теперь в них надо разобраться (а ведь на работе ещё и работу работать надо). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 11:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Правильно ли я понимаю, нужно каждый раз проходиться по всему массиву данных и выполнять определённого рода расчёты? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич...Где первая строка есть указатель времени, координаты и высоты. вторая и ещё одна где-то по середине - указатель энергии нейтронов (тепловые, быстрые), цифры - значения поля в конкретном твэле для указанных выше времени, энергии, ТВС и высоты. Так же есть небольшой файл перегрузок. Для примера что мне надо: Поиск ТВС, твэла, участка твэла с наибольшим флюэнсом (накопленной радиацией), по сути обычный интеграл(сумма) для конкретного участка от времени. Всевозможные зависимости плотностей потока от высоты, времени по каналу, времени для конкретной ТВС, по сечению. Поиск всяких максимумов и минимумов, перекосов. База данных справится с поиском/нахождением максимума/минимума лучше, чем свои собственные придумки. К тому же при ее использовании нет необходимости держать весь массив в памяти. Остается интеграл, подсчет которого может занять некоторое время, но опять же можно делать свои внешние функции. Правда, для этого надо подучить какую-нибудь субд. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:13 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyS.G.С такими данными, рано или поздно вам придется использовать СУБД. Для таких блобов (~75GB) СУБД нафиг не нужна. Только руками, только хардкор.очевидно, тут нет блоб-ов, как таковых, есть одни числа. да еще они относительно удобно сгруппированы для расположения их в нормальной форме. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:16 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUАндрей Игоревич, Правильно ли я понимаю, нужно каждый раз проходиться по всему массиву данных и выполнять определённого рода расчёты? Ну как нужно... Хотелось бы, естественно можно по разному решить одну задачу. Можно сразу сформулировать все задачи и разок пройтись. Но, как это часто бывает, новые задачи формируются только когда увидишь результаты решения предыдущих :). В общем я задачу понял, учить СУБД :). По мере возможности и наличия времени буду ковыряться. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:32 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUАндрей Игоревич, Правильно ли я понимаю, нужно каждый раз проходиться по всему массиву данных и выполнять определённого рода расчёты? "великий оптимизатор" почуял жертву )) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:33 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, MSSQL с такими файлами справляется на раз, в считанные секунды. Хранимка обеспечит всю обработку. https://msdn.microsoft.com/ru-ru/library/ms188365(v=sql.120).aspx ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
GerasimenkoАндрей Игоревич, MSSQL с такими файлами справляется на раз, в считанные секунды. Хранимка обеспечит всю обработку. https://msdn.microsoft.com/ru-ru/library/ms188365(v=sql.120).aspx Oracle тоже ! ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:34 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorGerasimenkoАндрей Игоревич, MSSQL с такими файлами справляется на раз, в считанные секунды. Хранимка обеспечит всю обработку. https://msdn.microsoft.com/ru-ru/library/ms188365(v=sql.120).aspx Oracle тоже ! Вот поверишь, никогда не сомневался!? :) Даже FoxPro под DOS должен справится (но там импорт медленнее будет работать)... Вопрос, что есть в конторе у автора. А ведь у них наверняка что-то есть. ТС-у просто на профильном форуме нужно задать несколько вопросов, а не изобретать велосипед... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Gerasimenkodefecatorпропущено... Oracle тоже ! Вот поверишь, никогда не сомневался!? :) Даже FoxPro под DOS должен справится (но там импорт медленнее будет работать)... Вопрос, что есть в конторе у автора. А ведь у них наверняка что-то есть. ТС-у просто на профильном форуме нужно задать несколько вопросов, а не изобретать велосипед... ну так и я про то же намекнул )) ты вот MSSQL вдруг упомянул, я - Оракле. Масло масляное )) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:41 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Обрати внимание на CachedTexts и CachedBuffers . Из всего предложенного - это самый производительный вариант Но да, лучше предварительно переводи текстовый файл в бинарный ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:43 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:47 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
S.G.очевидно, тут нет блоб-ов, как таковых, есть одни числа. да еще они относительно удобно сгруппированы для расположения их в нормальной форме. Кто-же знал, что у автора файлы текстовые... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
S.G.Андрей Игоревич...Для примера что мне надо: Поиск ТВС, твэла, участка твэла с наибольшим флюэнсом (накопленной радиацией), по сути обычный интеграл(сумма) для конкретного участка от времени. Всевозможные зависимости плотностей потока от высоты, времени по каналу, времени для конкретной ТВС, по сечению. Поиск всяких максимумов и минимумов, перекосов. База данных справится с поиском/нахождением максимума/минимума лучше, чем свои собственные придумки. К тому же при ее использовании нет необходимости держать весь массив в памяти. Остается интеграл, подсчет которого может занять некоторое время, но опять же можно делать свои внешние функции. Правда, для этого надо подучить какую-нибудь субд. да, при таком уточнении задачи соглашусь - если загнать все в нормальную базу, остается чистый SQL - гибко и универсально. что хочешь то и ищи, как хочешь - так и агрегируй. Какую из бесплатных баз брать.... MsSqlServer Express или Postgress, как мне кажется. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyS.G.очевидно, тут нет блоб-ов, как таковых, есть одни числа. да еще они относительно удобно сгруппированы для расположения их в нормальной форме. Кто-же знал, что у автора файлы текстовые... так автор написал, что текстовые 20918290 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:52 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov Какую из бесплатных баз брать.... MsSqlServer Express или Postgress, как мне кажется. Firebird тоже пережует и не подавится. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:53 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
В базу, мне кажется, всё всунуть и не мудрить. Postgress вполне подойдет, при том, что бесплатная. После конвертации из текста, скорее всего, станет меньше. Считать потом можно что угодно и как угодно - как придумаете. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 12:59 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorтак автор написал, что текстовые 20918290 Я описание задачи в первом сообщении читал. Там речь идёт о 10 ярдах чисел, одновременно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 13:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Да и FB, думаю. Важно понимать простую вещь. Что базы как раз для того и придуманы, что бы не городить гору кода самому. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 13:05 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
makhaonЧто базы как раз для того и придуманы, что бы не городить гору кода самому. Позиционирование в типизированном файле это не гора кода, и работать будет ,скорее всего, быстрее. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 13:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey, +1. А еще - простые решения как правило самые лучшие. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 13:31 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Я так понял здесь две проблемы. Первая сформировать бинарник за адекватное время. Вторая работа с бинарником. Первое - относительно просто. Для второго, предложил бы сделать транслятор данных массива над буфферизированным потоком (коих хватает на просторах интернета), что тоже довольно простая задача. Вот правда среду бы посоветовал юзать с генерацией х64 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 13:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
авторПозиционирование в типизированном файле это не гора кода, и работать будет ,скорее всего, быстрее. Пока нужно по массиву пробежаться и просто сложить - то да. Но в его случае этим, скорее всего, не закончится. Аппетит приходит во время еды. Начнется сортировка, поиск, деление на группы, индексы и так далее. И то, что можно сделать простым запросом в пару строк в коде будет выглядеть довольно громоздко. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreatKazantsev Alexey, +1. А еще - простые решения как правило самые лучшие. А я склоняюсь именно к БД. 1 раз пишется импорт данных - а дальше крути как хочешь - сервер тебе в этом только поможет. А с учетом разнообразных хотелок по извлечению данных и их анализу - простое решение вырастет в такого себе монстрика. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:19 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
DarkMaster, Нет, тако можно, но это как гвозди гидравлическим прессом забивать. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:21 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreatDarkMaster, Нет, тако можно, но это как гвозди гидравлическим прессом забивать. ты хочешь сказать, что БД с готовыми алгоритмами для задачи ТС не нужна ? или я тебя не понял ? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:24 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecator, Далеко не обязательна. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
БД хорош тем, что алгоритмы и индексацию можно масштабировать Но когда речь идёт о терабайтах данных и алгоритмы предполагают последовательную обработку всех данных - СУБД будет существенно тормозить этот процесс. Тем более можно сделать пул потоков и обрабатывать массив сразу на нескольких ядрах. Вопрос, на сколько прямая обработка данных будет быстрее СУБД. Я думаю раза в 2-3. Но реальную цифру мы можем сказать только проведя реальные тесты Поэтому предлагаю замутить тестовый открытый репозиторий на битбакете и проверить ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:48 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUБД хорош тем, что алгоритмы и индексацию можно масштабировать Но когда речь идёт о терабайтах данных и алгоритмы предполагают последовательную обработку всех данных - СУБД будет существенно тормозить этот процесс. Тем более можно сделать пул потоков и обрабатывать массив сразу на нескольких ядрах. Вопрос, на сколько прямая обработка данных будет быстрее СУБД. Я думаю раза в 2-3. Но реальную цифру мы можем сказать только проведя реальные тесты Поэтому предлагаю замутить тестовый открытый репозиторий на битбакете и проверить Что ты хочешь тестировать ? очевидное-невероятное ? Опять сел на своего любимого конька ? Через СУБД будет медленнее, но это будет компенсироваться гибкостью хранения, индексирования и готовыми механизмами анализа данных. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 14:56 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorЧто ты хочешь тестировать ? Как что? Сформулируем несколько задач - и каждую из них прогоним Автор, кстати, уже говорил, что ему нужен поиск твела/ТВС, суммирование данных ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 15:09 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUПоэтому предлагаю замутить тестовый открытый репозиторий на битбакете и проверить Чем закончился твой предыдущий челендж с XML? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 15:28 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey, Никому кроме меня не интересны реальные тесты. Все только языком чесать горазды ) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 15:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
02.11.2017 15:58, SOFT FOR YOU пишет: > Никому кроме меня не интересны реальные тесты. Все только языком чесать горазды )  Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 16:08 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUБД хорош тем, что алгоритмы и индексацию можно масштабироватьможно даже data mining/analytics устроить коробочными ср-вами SOFT FOR YOUНо когда речь идёт о терабайтах данныхэто даже не особо и big data SOFT FOR YOUТем более можно сделать пул потоков и обрабатывать массив сразу на нескольких ядрахраспараллелить разумеется можно и в бд SOFT FOR YOUна сколько прямая обработка данных будет быстрее СУБДумеющий и любящий рукоблудить возможно и добьется а если не особо специалист то вероятно легче/удобнее будет освоить специализированный инструментарий/dsl ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 16:16 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavan, Не факт, что у ТС сервер с ксеоном на 28 ядер и винтом на 3GB/s Поэтому, не смотря на возможности, производительность такого решения с 1 минуты может возрасти до пары часов Никто не говорит, что так нельзя. Я лишь говорю, что топорным методом (подобрав инструментарий) задача отработает за считанные секунды Лично мне интересно проверить, какова разница по производительности ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 16:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Как обычно: ТС "потерялся", а топик зафлудили Андрей ИгоревичНу файлы по 2-3 гб, просто их до 20 штук. (Один файл - один год эксплуатации) SOFT FOR YOU Лично мне интересно проверить, какова разница по производительности Как предлогали ранее, текстовые файлы нужно перегнать в бинарные. А seek + blockread будет быстрее, чем выборка через СУБД ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 17:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
НезваныйГостьКак обычно: ТС "потерялся", а топик зафлудили Андрей ИгоревичНу файлы по 2-3 гб, просто их до 20 штук. (Один файл - один год эксплуатации) SOFT FOR YOU Лично мне интересно проверить, какова разница по производительности Как предлогали ранее, текстовые файлы нужно перегнать в бинарные. А seek + blockread будет быстрее, чем выборка через СУБД Ну я "потерялся" в том плане, что даже не знаю, что ответить на такие предложения. Мне бы для начала разобраться как всё это работает. Пока вот работы на работе подвалило - некогда, а дома сил уже не хватает :(. Дайте хоть неделю-две поковыряться в ваших предложениях :). Мне тут уже столько всего напредлогали. И классы, и многопоточная загрузка текста при помощи каких-то библиотек, и ещё куча всего, в чем я пока с трудом разбираюсь. А я ведь просто хотел подгрузить массив и способом "Фор И ту Ж ду" решить большинство интересующих меня задач. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 17:28 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
НезваныйГостьКак предлогали ранее, текстовые файлы нужно перегнать в бинарные. А seek + blockread будет быстрее, чем выборка через СУБД Ну вот скажи мне плиз, как твои сверхбыстрые Seek/BlockRead справятся с задачей "найти первые 100 вхождений числа 1.23455" в диапазоне дат от .. до ..? Дело не в том, как быстро прочитать - с данными еще и работать нужно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 17:30 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, А ты по шагам разбей - решай задачи по мере их поступления. Я бы сделал следующее (ага, это я со своей колокольни) : выбрал бы СУБД (не ведись на Oracle и Postge - их еще готовить нужно уметь). Перегнал бы данные в БД и начал бы учить SQL (там реально все несложно) - считай, что 90% твоих задач уже можно решить с помощью уже готовых средств (sql-запросами). При возникновении конкретных проблем (при перегонке данных, тормозах при выборке и т.п.) - обращался бы сюда. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 17:36 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
02.11.2017 17:28, Андрей Игоревич пишет: > А я ведь просто хотел подгрузить массив и способом "Фор И ту Ж ду" решить большинство интересующих меня задач. :) я ж сказал чем это можно сделать: Compaq Array Visualizer. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 17:41 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичА я ведь просто хотел подгрузить массив и способом "Фор И ту Ж ду" решить большинство интересующих меня задач. :) Для начала тебе нужно решить, все свои алгоритмы ты будешь проверять на бинарных данных или на текстовых? Если на текстовых, можно так: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. Если бинарные данные, то по простому можно так: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 18:15 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
DarkMasterНу вот скажи мне плиз, как твои сверхбыстрые Seek/BlockRead справятся с задачей "найти первые 100 вхождений числа 1.23455" в диапазоне дат от .. до ..? Никак. Первоначальный вопрос ТС: "Как работать с массивом около 10 миллиардов (1е10) значений типа реал". Дальше ТС уточнил: "...по сути обычный интеграл(сумма) для конкретного участка от времени. Всевозможные зависимости плотностей потока от высоты, времени по каналу, времени для конкретной ТВС, по сечению. Поиск всяких максимумов и минимумов, перекосов." Придуманной задачи о вхождении и диапазона дат не ставится, хотя циклы и операторы сравнения никто не запрещал и не отменял . ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 23:09 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Да чё вы мозги полощите Давайте тесты в студию :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.11.2017, 23:22 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
НезваныйГостьПридуманной задачи о вхождении и диапазона дат не ставитсяАндрей Игоревичновые задачи формируются только когда увидишь результаты решения предыдущих ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 09:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Повторюсь. Аппетит приходит во время еды. А тут уже всё написано. И что бы аппетит удовлетворить приходится всё переписывать с нуля. И кому это нужно? :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 11:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
DarkMasterАндрей Игоревич, А ты по шагам разбей - решай задачи по мере их поступления. Я бы сделал следующее (ага, это я со своей колокольни) : выбрал бы СУБД (не ведись на Oracle и Postge - их еще готовить нужно уметь). Перегнал бы данные в БД и начал бы учить SQL (там реально все несложно) - считай, что 90% твоих задач уже можно решить с помощью уже готовых средств (sql-запросами). При возникновении конкретных проблем (при перегонке данных, тормозах при выборке и т.п.) - обращался бы сюда. А как лучше спроектировать схему данных.... Для меня вот неочевидно. получается, что основная табличка что-то вроде id_твел-а, тип-нейтронов(тепловые-быстрые, или как там?), дата-измерения, показатель. может еще на каждом твэле куча отсчетов по высоте, или еще чему-то там, я не представляю себе как это по жизни..... я это к чему - к тому что в таком нормализованном представлении на 1 отсчет не так мало инфрастуктуры и базка может и распухнуть.... тут бы примерно прикинуть хотя бы, для какого сервера БД какую железку надо под задачку. чтобы комфортно крутить данными. Я такую прикидку не возьмусь сделать.... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 14:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir BaskakovЯ такую прикидку не возьмусь сделать.... Есть у нас тут один специалист. Большой знаток оптимизаций в БД и вообще СУБД :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 14:40 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
SOFT FOR YOUЕсть у нас тут один специалист. Большой знаток оптимизаций в БД и вообще СУБД :) И ваши чувства, кажется, взаимны ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 14:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey, Нет у меня никаких чувств. Просто есть забавный персонаж, который только на словах Лев Толстой :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 03.11.2017, 15:14 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
defecatorGerasimenkoАндрей Игоревич, MSSQL с такими файлами справляется на раз, в считанные секунды. Хранимка обеспечит всю обработку. https://msdn.microsoft.com/ru-ru/library/ms188365(v=sql.120).aspx Oracle тоже ! Я как бы ораклист, хотя и непродвинутый, и у меня вопрос - а оно в бесплатный оракул влезае? А то платный, он небесплатный. (Каламбур). и какое нужно железо..... ну не ложится у меня в душе схема данных, хоть в каше с мампсом (храни нас эволюция) посылай. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 04.11.2017, 10:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Потихоньку разбираться в ваших предложениях, читать про СУБД, как я понял в теме мне суммарно предложили 3 варианта обработки данных: 1. БД (Оракл, Парадокс, всякие SQL и ещё что-то там). 2. Кешировать массив на диске. 3. Куча способов прямого многопоточного считывания данных посредством всяких библиотек и прямой работы с ними. Про БД, вроде любопытно, хотя и ощущается как костыль, но пока только вникаю. Хотя освоение SQL явно пока отложу. Посоветуйте СУБД максимально простую в освоении для начала. И вопрос, как реализовать? Как одну огромную таблицу типа Код: pascal 1. 2. 3. 4. Где ключ первые 5 столбцов или иерархически: Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. Где всё - отдельные таблицы (чет много будет таблиц), второй столбец каждой таблицы - ключ, первый - индекс от ключа предыдущего уровня (как он там называется) . Но вообще, как-то сложно :), сначала файлы как-то надо перегнать всё БД, потом на ходу считывать и с этим работать, потом удалять (а ведь мне подобные данные массивы по 3 раза в месяц иногда приходят). Про кеширование, я так понимаю это возможно только на Делфи 64, ибо мой компилятор просто не компилирует подобную запись с формулировкой "массив больше 2 гб". Вопрос - где взять Делфи 64? В итоге я склоняюсь к многопоточной прямой работе с файлами, то есть сначала перегоняю их в типизированные файлы, а потом подгружаю их по мере формирование запросов? По крайне мере просто реализуется и понятно логичкски. Варианты "поднять\использовать сервер" - не рассматриваю, не то что бы у меня не было такой возможности, но это как-то слишком для такой задачи. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.11.2017, 19:41 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичПро кеширование, я так понимаю это возможно только на Делфи 64 Не обязательно. В windows есть механизм отображения файлов в память (file mapping). Буферизацией в этом случае занимается операционная система. Если у вас win64 и более 4G оперативной памяти, то в этом случае есть смысл подумать о 64-битном компиляторе. Вместо Delphi можно посмотреть в сторону Lazarus . пример использования File Mapping для x86 (32 бита) Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.11.2017, 22:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичПотихоньку разбираться в ваших предложениях, читать про СУБД, как я понял в теме мне суммарно предложили 3 варианта обработки данных: 1. БД (Оракл, Парадокс, всякие SQL и ещё что-то там). 2. Кешировать массив на диске. 3. Куча способов прямого многопоточного считывания данных посредством всяких библиотек и прямой работы с ними. Про БД, вроде любопытно, хотя и ощущается как костыль, но пока только вникаю. Хотя освоение SQL явно пока отложу. Посоветуйте СУБД максимально простую в освоении для начала. И вопрос, как реализовать? Как одну огромную таблицу типа Код: pascal 1. 2. 3. 4. Под описанную задачу так и просится Cache' - там вся база как огромный многомерный массив. http://docs.intersystems.com/csp/docbook/DocBook.UI.Page.cls?KEY=GGBL_intro ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 09:45 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir BaskakovЯ как бы ораклист, хотя и непродвинутый, и у меня вопрос - а оно в бесплатный оракул влезае?последние годы в оракле есть опция in-memory с колоночным хранением что позитивно сказывается на скорострельности аналитических запросов но есть ли оно во фришной редакции тоже не скажу ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 11:05 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичПотихоньку разбираться в ваших предложениях, читать про СУБД, как я понял в теме мне суммарно предложили 3 варианта обработки данных: 1. БД (Оракл, Парадокс, всякие SQL и ещё что-то там). 2. Кешировать массив на диске. 3. Куча способов прямого многопоточного считывания данных посредством всяких библиотек и прямой работы с ними. Про БД, вроде любопытно, хотя и ощущается как костыль, но пока только вникаю. Хотя освоение SQL явно пока отложу. Посоветуйте СУБД максимально простую в освоении для начала. И вопрос, как реализовать? Как одну огромную таблицу типа Код: pascal 1. 2. 3. 4. Где ключ первые 5 столбцов или иерархически: Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. Где всё - отдельные таблицы (чет много будет таблиц), второй столбец каждой таблицы - ключ, первый - индекс от ключа предыдущего уровня (как он там называется) . Но вообще, как-то сложно :), сначала файлы как-то надо перегнать всё БД, потом на ходу считывать и с этим работать, потом удалять (а ведь мне подобные данные массивы по 3 раза в месяц иногда приходят). Про кеширование, я так понимаю это возможно только на Делфи 64, ибо мой компилятор просто не компилирует подобную запись с формулировкой "массив больше 2 гб". Вопрос - где взять Делфи 64? В итоге я склоняюсь к многопоточной прямой работе с файлами, то есть сначала перегоняю их в типизированные файлы, а потом подгружаю их по мере формирование запросов? По крайне мере просто реализуется и понятно логичкски. Варианты "поднять\использовать сервер" - не рассматриваю, не то что бы у меня не было такой возможности, но это как-то слишком для такой задачи. Я бы делал один большой ключ. - все параметры - показатель. то есть, в одну таблицу. Не надо особенно сильно боятся установки сервера, ну сервер и сервер. Некоторые ставятся в режиме да-да-да-да. В оракле таблицы можно партиционировать, то есть делить данные допустим по периодам, если запрос позволяет сразу определить нужную партицию (партиции) - данные конечно возвращаются быстрее. В других базах тоже, можно - про файербёрд не знаю, а в постгрессе вроде было. но, опять таки, хорошо бы понимать, что у Вас с дисками и оперативкой - БД - это не волшебная палочка. жаль, что более опытные базовики не отреагировали на вопрос о проектировании. Возможно, стоит продублировать вопрос в разделах баз, конкретно - firebird, ms sql server. postgress, mySql. Оракл все же ставить посложнее, лучше не надо, а эти четыре - нормально. Базы без сервера, типа акцесса, к такой работе не приспособлены. но если хотите попробовать, то попробуйте http://www.webdelphi.ru/2016/08/sqlite-v-delphi-bolshoj-obzor-i-litedac-v-primerax/ - предполагаю, что разочарует. разве что, если загонять разные срезы в несколько файлов данных..... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 12:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
ой, посмотрел, не надо SQLite - •не рекомендован для баз большого размера (эксперты не рекомендуют более 200 Мб); • есть только два типа данных – целое автоинкримент и строка (всё остальное – эмулируется через строки); • не предназначен для многопользовательского использования (хотя это и возможно). а попробуйте для начала как DarkMaster говорил - Firebird, одна таблица, просто вставить нужное количество записей - какого размера станет файл БД, на глаз, ну и пару запросов - хоть тупо сумму по всем полям - сколько протормозит. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 12:08 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
я рекомендую MS SQL, он прост в установке и комплектом идет Management Studio. Ну и инструменты массовой загрузки. Postgree также несложно ставится, но на windows только в целях тестирования/разработки, и по умолчанию его настройки совсем неоптимальны, все будет ужасно медленно работать Oracle сложнее ставить, да и ИМХО не для новичков. Про Firebird ничего сказать не могу - не работал. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 12:56 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
FB ставится минуты за 2 минуты. Если IBEXprert'ом делать базу - то простую таблицу сделать - несколько минут. Им же можно залить данные в базу. Им же погонять запросы. В целом - то Делфи нужна больше для отображения результатов. Так то всё можно и в эксперте погонять, для оценки производительности, думаю, вполне его достаточно безо всякого кода. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 14:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
- Коллега крутил постгресс под виндой, и вроде проблем не было. Сам не пробовал, врать не буду, но так мне хвалили. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 14:42 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
ИМХО, прав был тот, кто советовал работать с двоичными файлами. Создайте из ваших сырых данных несколько двоичных файлов, разбитых по смыслу и, возможно, по времени так, чтобы их можно было полностью загрузить в память. Загрузили, обсчитали один файл, сохранили результат, загрузили, обсчитали следующий. СУБД может дать очень большие накладные расходы, если данные надо не искать, а обрабатывать последовательно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 15:32 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Я бы свел к двоичному файлу со структурой как у таблицы. Измерение1, Измерение2, Измерение3, Измерение4, Измерение5, Значение ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 15:50 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Шавлюк ЕвгенийЯ бы свел к двоичному файлу со структурой как у таблицы. Измерение1, Измерение2, Измерение3, Измерение4, Измерение5, ЗначениеТолько Значение. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.11.2017, 16:30 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
bk0010ИМХО, прав был тот, кто советовал работать с двоичными файлами. Создайте из ваших сырых данных несколько двоичных файлов, разбитых по смыслу и, возможно, по времени так, чтобы их можно было полностью загрузить в память. Загрузили, обсчитали один файл, сохранили результат, загрузили, обсчитали следующий. СУБД может дать очень большие накладные расходы, если данные надо не искать, а обрабатывать последовательно. так тут вопрос железа. Потянет или нет накладные расходы, за которые можно будет получать удобство и гибкость. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 11:22 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
bk0010Только Значение. Согласен. Делаем пустой файл размером 20*60*60*163*312*sizeof(real) По мере чтения заполняем значения сразу на нужное место. В итоге файл получится индексированным. Навигация по нему станет тривиальной ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 13:31 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Шавлюк Евгений, Да, подумаешь, всего 21 гиг... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 14:48 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Cobalt747, А разве это проблема? Не грузить же его единоразово в память? В виде БД все равно будет больше ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 15:32 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Cobalt747Шавлюк Евгений, Да, подумаешь, всего 21 гиг... угу. Но - база с ее накладными расходами это все минимум удвоит-утроит. И, на этом фоне вопрос о том, какая из бесплатных это хорошо потянет и на каком железе, очевидным не выглядит. так же неочевидно, что например фортран автоматом поможет сделать все просто и прозрачно. над организацией данных все равно надо поразмышлять.... может быть, хранить предрассчитанные агрегаты.... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 15:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakovбаза с ее накладными расходами это все минимум удвоит-утроит. Вот вот. Базу имеет смысл использовать только если задача по анализу стоит достаточно сложная. Причем сложность заключается в требуемой множественности подходов к выборке данных. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 15:36 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, Да и из такого файла в базу перелить несложно, вот из исходных текстовых - сложнее. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.11.2017, 16:30 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
еще я бы подумал над группировкой (агрегацией) данных до такой степени, чтобы агрегированный массив влезал в 2Гб (или, для случая использования 64-битного компилятора, во всю имеющуюся оперативку) - возможно, это ускорило бы решение некоторых задач. если нужны разные виды агрегирования (сумма, мин, макс, среднее и т.п.) - то несколько таких массивов хранить, естественно, в бинарных файлах ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.11.2017, 10:52 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
proposalесли нужны разные виды агрегирования (сумма, мин, макс, среднее и т.п.) - то несколько таких массивовили, для задач, где нужно более 1 агрегата - несколько агрегатов в 1 влезающем в память массиве ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.11.2017, 10:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Подниму старую свою тему на эту же тему, но не совсем. Решил я не в один массив всё закинуть, а в разные (уже для других целей) и вышла такая ошибка, очевидно, что те же превышения 2гб, если массивы чуть порезать - всё норм  как победить? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 15:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
X64 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 15:59 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, И как? Где его взять, или как запустить на том же Берлине или Токио (про 7 вообще молчу)? В выпадающем списке только win 32. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 16:45 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
bk0010Данные размещать не в стеке его не хватит: в x32 16 МБ максимум Что, простите? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 16:57 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичrgreat, И как? Где его взять, или как запустить на том же Берлине или Токио (про 7 вообще молчу)? В выпадающем списке только win 32. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 17:06 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, Отлично, спасибо, а то не мог найти где эта настройка). Правда после Делфи сразу крашнулся без выведения ошибок :), а теперь пишет в логе "Успех" и ничего не происходит). Но уже прогресс. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 17:21 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Весело у тебя там. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 17:31 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, В общем попробовал на другом компе Берлине, при попытке компиляции с 2 массивами превышающими 1,5 gb каждый всё крашится: делфи крашится, программа крашится, модули системные и те крашатся. При том даже в 64 битной версии сделать один массив более 2 ГБ не дает.  Что делать, как быть? Как дальше жить? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 22:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Какой у тебя хоть тип-то "больше 2 гб"? Телепатией не владею. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 22:19 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Квейдbk0010Данные размещать не в стеке его не хватит: в x32 16 МБ максимум Что, простите?Попробуйте, сюрприз будет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 22:32 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
bk0010Попробуйте, сюрприз будет. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 22:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, rgreat, Да всё то же самое, что и начале темы. Андрей ИгоревичМассив задан записью: рекорд[1..3] of рекорд[1..20] of рекорд[1..60] of рекорд[1..60] of рекорд[1..163] of рекорд[1..312] of real с кучей побочных параметров на каждом уровне. Ну только теперь Код: pascal 1. если это что-то меняет :). Мне либо так задать, либо просто два раза по Код: pascal 1. В первом случае ругается, во втором - крашится. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, В общем то банальный Код: pascal 1. тоже выдаёт ограничения в 2 ГБ, правда несколько таких массивов не крашат делфи. Размер стека поставил на максимум разрешенного. В принципе можно и обычными массивами обойтись для конкретно этой задачи, но всё-таки, чего он не работает-то :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:07 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexeybk0010Попробуйте, сюрприз будет. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. А Delphi у вас какая? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, как же не хватает возможности редактировать пост, а не заниматься "оверпостингом". О вышла ошибка до краша делфи "stack_oveflow", хм, при каждой компиляции программы Делфи ведет себя по разному :). И как мне уже с этой бедой бороться, если уже стоит максимальный размер стака. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:21 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
bk0010А Delphi у вас какая? 2006 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Самое время отказаться от статических массивов и перейти на динамические. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey, Чтоб программа крашилась не сразу, а к моменту превышения некой величины? Не очень хочется иметь такою нестабильную программу. Крупные обрабатываемые файлы как раз забивают всю указанную выше запись. По сути чтоб программа не работала достаточно такого кода Код: pascal 1. 2. 3. 4. 5. 6. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyАндрей Игоревич, Самое время отказаться от статических массивов и перейти на динамические. Святые слова  ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:33 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Это баги компилятора ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичЧтоб программа крашилась не сразу, а к моменту превышения некой величины? Чтобы не упираться в ограничение на размер статических типов. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.01.2018, 23:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич Код: pascal 1. Не надо так делать и все заработает. Если памяти у вас хватит. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 01:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreat, Что-то не особо оно работает. В итоге делфи завис и только убивать через диспетчер. Памяти должно хватать.  НяшикЭто баги компилятора И как быть? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 09:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичИ как быть?Кто сказал что должно хватать? Нужны непрерывные участки, а таких может и не быть (особенно в W10 FCU). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:10 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Не знаю, что у вас там и как. Попробовал на XE6, выполнилось без особенностей. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:10 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_nigger, да, может в этом и проблема. что памяти не хватает. что бы кусок выделить целиком. у меня схавало без вопросов. скорее всего многомерные массивы придётся делать. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичrgreat, Что-то не особо оно работает. В итоге делфи завис и только убивать через диспетчер. Памяти должно хватать. НяшикЭто баги компилятора И как быть? арендовать виртуальную машину с дохренищей памяти и поставить там языки с библиотеками для обработки больших массивов (((( а пока попробуйте использовать для выделения памяти https://msdn.microsoft.com/ru-ru/library/windows/desktop/aa366887(v=vs.85).aspx VirtualAlloc ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
makhaonда, может в этом и проблема. что памяти не хватает. что бы кусок выделить целиком. у меня схавало без вопросов. скорее всего многомерные массивы придётся делать. Ну 16 ГБ оперативы и столько же в подкачке. Сколькож ему надо? В диспетчере информация неактуальная какая-то. При том что любопытно, сделал увеличение массива по кнопке - работает, а не при инициализации, заполнил рандомами - работает (на удивление быстро забивает 400 миллионов значений). Возвращаюсь к своим "записям", делаю вместо двух переменных динамический массив, по кнопке выполняю SetLength(array, 2), вроде бы работает, подключаю процедуру для работы с массивом - программа вылетает (правда уже без краша компилятора) с формулировкой нет доступа к какой-то там ячейке памяти. При том программа вылетает не в момент увеличения массива, и не в момент первого обращения к нему, а момент инициализации процедуры в котором должны обращаться к массиву. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:27 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov, Да не такие уж это даже и большие массивы, чтоб так с ними морочится, в пространственных расчетах массивы по сотни гигабайт бывают. Правда хз как там их обрабатывают. Хотя и у программ для таких расчетов обычно жесткие требования к оперативе 64-128гб. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 10:32 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, с самого начала вам предлагали БД. После можно было обрабатывать данные целиком или засасывать кусками в память и перекручивать их там. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:03 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичНу 16 ГБ оперативы и столько же в подкачке. Сколькож ему надо? В диспетчере информация неактуальная какая-то.В общем случае 32-бит процессу из этих 16 гигов достается лишь 2 гига. Остальное зависит от фрагментации. Там может быть свободно более 1 гиг, но иза фрагментации, не быть свободного куска нужного размера. И попытка его выделить потерпит неудачу ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:15 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
200000000 это всего лишь 200 байт мегабайт ... Оперативной памяти у меня к примеру должно хватит 100% Та и под 64 битным компилятором тоже не работает данный код  ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:34 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
LocksmithPC, БД это хорошо, я даже поковырялся немного, но пока отказался от данного способа из-за слишком большого количества телодвижений ради каждой операции. Возможно позже опять к нему вернусь. Тут то вроде массив куда меньший изначального, всего около 400 миллионов значений по 4 байта (real) - по идее всего-то 1-3 гб памяти. Мучать БД ради такого не хотелось бы. white_niggerВ общем случае 32-бит процессу из этих 16 гигов достается лишь 2 гига. Остальное зависит от фрагментации. Там может быть свободно более 1 гиг, но иза фрагментации, не быть свободного куска нужного размера. И попытка его выделить потерпит неудачу Да вроде и процессор и система 64, и компилятор на 64 убедил работать. Как его (компилятор, приложение) убедить отжать в памяти более 2гБ сразу, не фрагментируя данные? Куча программ под себя и по 100ГБ забирает оперативы, и не жалуется. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичпрограмма вылетает (правда уже без краша компилятора) с формулировкой нет доступа к какой-то там ячейке памяти Значит где-то косячишь с индексом/обращаешься к неинициализированной переменной. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:36 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Няшик200000000 это всего лишь 200 байт мегабайт ... Оперативной памяти у меня к примеру должно хватит 100% Та и под 64 битным компилятором тоже не работает данный код Ну реал вроде 4(6?) байта, так что такие 800 где-то 800 мб, но всё равно не так уж и много, чтоб не хватало памяти. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerНужны непрерывные участки, а таких может и не быть (особенно в W10 FCU) Непрерывные участки в адресном пространстве процесса. Как FCU на это может повлиять? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:39 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичНу реал вроде 4(6?) байта Довольно давно уже Real = Double. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:40 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, О да.. Я помножить забыл 200 000 000 * 8 байт = 1600 Мбайт 8 он байт ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:41 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyКак FCU на это может повлиять?По идее не должен. Хотя в FCU мелкомягкие накосячили с выделением памяти - сильная фрагментация. Может косвенно как-нить и влияет ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:48 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичКак его (компилятор, приложение) убедить отжать в памяти более 2гБ сразу, не фрагментируя данные? Код для x64: Код: pascal 1. 2. 3. 4. 5. Прекрасно работает на виртуальной машине с 1Gb RAM. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. Делфей нет. Но под FPC вроде отработало. я уж правда наизусть не помню, сколько байт в Real ((( ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerХотя в FCU мелкомягкие накосячили с выделением памяти - сильная фрагментация. У дельфей же свой ММ, ему системная фрагментация побоку. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, авторНу 16 ГБ оперативы и столько же в подкачке. Сколькож ему надо? В диспетчере информация неактуальная какая-то. если бы с памятью было всё так просто ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 11:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyУ дельфей же свой ММ, ему системная фрагментация побоку.Ну я как бы в курсе :) Он один фиг поверх системного аллокатора, а если тот может глючить... Я не настаиваю, просто в случае FCU ничему не удивляюсь ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:00 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey, думаешь, что мм прямо с железом работает? посмотри хотя бы тот же fastmm: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_nigger, Как я понимаю, VirtualAlloc может просто не вернуть кусок нужного размера из-за фрагментации. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:04 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexeywhite_niggerНужны непрерывные участки, а таких может и не быть (особенно в W10 FCU) Непрерывные участки в адресном пространстве процесса. Как FCU на это может повлиять? Как минимум - смотря как дллки на пространство аллоцирированы. Хотя обычно винда их прибирает кверху, насколько я помню. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:06 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov, Отработало. Hello, world. 4.00000000000000E+0001 В диспетчере память - 5.7 мб Дабавим полное заполнение, for и ошибка 32 бит  64 бит  Протестируй у себя Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:07 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
white_niggerОн один фиг поверх системного аллокатора, а если тот может глючить... Хочешь сказать, что на FCU глючит VirtualAlloc? makhaonКак я понимаю, VirtualAlloc может просто не вернуть кусок нужного размера из-за фрагментации Ты бы ещё понимал о чём говоришь... Чтобы VirtualAlloc обломался из-за фрагментации, у тебя в процессе должны быть зарезервированы участки памяти по множеству адресов, между которыми не находится достаточно свободного места. А того пространства у тебя 8TB. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
p:=VirtualAlloc(nil,8*200000000,MEM_COMMIT ,PAGE_READWRITE); а так - сдохло. вот так p:=VirtualAlloc(nil,4*200 000 000,MEM_COMMIT ,PAGE_READWRITE); p2:=VirtualAlloc(nil,4*200000000,MEM_COMMIT ,PAGE_READWRITE); работает...... в общем, там по адресации надо посмотреть. и на крайняк резать на куски. в принципе, ну два куска. Ну что поделать? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyА того пространства у тебя 8TB ... с IMAGE_FILE_LARGE_ADDRESS_AWARE ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov, Код: pascal 1. 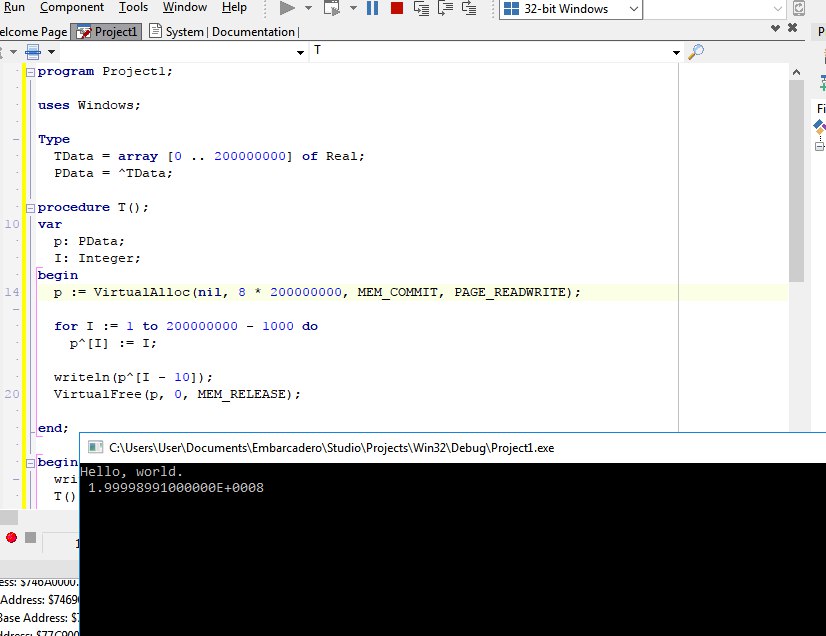 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
НяшикVladimir Baskakov, Отработало. Hello, world. 4.00000000000000E+0001 В диспетчере память - 5.7 мб Дабавим полное заполнение, for и ошибка Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. так - у меня - не падает. Фри паскалю никаких флагов не ставил, без понятия во что компилит. 8*200000000 - так - упадет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:31 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov, Никогда не пиши цифры. Лучше пиши так Код: pascal 1. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:34 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov8*200000000 - так - упадет. Обычный SetLength(doubles, 200000000); прекрасно отрабатывает на XP-виртуалке с 1Gb. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyVladimir Baskakov8*200000000 - так - упадет. Обычный SetLength(doubles, 200000000); прекрасно отрабатывает на XP-виртуалке с 1Gb. Чисто для чистоты эксперимента, я речь вел о двух таких массивах. :). А вообще хз, у меня через раз нормально работает. Почему - пока не понял :). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:37 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. такой код падает при заполнении второго массива. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:46 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakov, У меня норм отработало Лучше сделай Код: pascal 1. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
А можно еще так: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyVladimir Baskakov8*200000000 - так - упадет. Обычный SetLength(doubles, 200000000); прекрасно отрабатывает на XP-виртуалке с 1Gb. FPC - работает Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. падает Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. вин 7-64 - 4 гига ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Няшик writeln(SIZEOF(Real)); я делал, 8. но у меня не делфя - раз, флаги компилятора не выставлены - два. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyАндрей Игоревичпрограмма вылетает (правда уже без краша компилятора) с формулировкой нет доступа к какой-то там ячейке памяти Значит где-то косячишь с индексом/обращаешься к неинициализированной переменной. Ага, и правда косячил (забыл что динамический массив с 0 начинается), присваивал "1" и "2", вместо "0" и "1", так что конкретно эта задача решена, прошу простить за невнимательность. Правда почему со статическим массивом не дает работать или крашится, всё равно не понятно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичЧисто для чистоты эксперимента, я речь вел о двух таких массивах. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 12:59 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичKazantsev Alexeyпропущено... Обычный SetLength(doubles, 200000000); прекрасно отрабатывает на XP-виртуалке с 1Gb. Чисто для чистоты эксперимента, я речь вел о двух таких массивах. :). А вообще хз, у меня через раз нормально работает. Почему - пока не понял :). Поделите массив между несколькими запусками программы - map-reduce, однако, бигдэйта. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
...виртуалка с 2Gb. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичПравда почему со статическим массивом не дает работать или крашится, всё равно не понятно. Вероятно есть ещё какие-то косяки, пока не обнаруженные ;) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:03 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakovпадает Проверил на fpc 3.1.1. работает и под линуксом и под вайном. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:07 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyVladimir Baskakovпадает Проверил на fpc 3.1.1. работает и под линуксом и под вайном. у меня нет кросскомпайлера -> 64. возможно - ограничение 32-разрядной программы. версия 3.0.2 i386w32 ... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:16 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Виртуалка с 2Gb и 4 массива (6.1Gb). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:18 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir Baskakovвозможно - ограничение 32-разрядной программы Если учесть, что по дефолту у 32-битного процесса адресное пространство всего 2Gb, то не удивительно, что при выделении таких объёмов можно легко налететь на его нехватку. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev AlexeyВиртуалка с 2Gb и 4 массива (6.1Gb).Долго диском шуршало? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Kazantsev Alexey(6.1Gb) Пардон, 5.9Gb. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
rgreatДолго диском шуршало? Неа :) Этож виртуалка, у неё хостовый кеш для дисковых операций. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 25.01.2018, 13:27 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Это опять я. Наверно данные вопросы можно задавать и в разделе Огнептицы, но связанны они всё с теми же большими массивами в том же Делфи, да и тут всё свои, советов надавали, теперь надо разобраться :). В БД я понимаю почти ничего, так что сильно прошу не унижать. В общем с разной степенью успешности попробовал разные БД и СУБД, остановился на InterBase с Firebird (а почему нет). И возникли следующие вопросы/проблемы: Общие: 1. Какие вообще БД можно использовать без поднятия сервера для указанных выше задач (массивы с 10кккк значений)? Если БД которые не требуют вообще никакой установки на "клиентском" компьютере, ну или отделаться одним фалом типа .ддл? Просто на основном рабочем компьютере абсолютный минимум прав, а дергать админа ради установки сервера., ну такое. 2. Какие БД можно подключить к 64 битному приложению на делфи? Ну и как это сделать Огнептицей (при переключении ругается)? По FireBird. 1. Банальный вопрос: как очистить файл БД? Код: plsql 1. удаляет значения, но не очищает базу, не знаю что там хранится (логи, резерв, история), но как очистить файл? 2. Серьёзный вопрос: запредельно медленное для моей задачи заполнение таблицы. Через процедуру в IBE массив в 500к значений заполняется единицами за 580 секунд, через прямую SQL команду за 500 секунд: код Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. Что при заполнении массива в 10кккк значений потребует всего-то 3-4 месяца. Можно, конечно, распараллелить и ждать всего-то месяц, но как-то что-то хз... Ну и вопрос: что я делаю в данном коде не так? Как можно ускорить заполнение (ну там транзакции по другому проводить или ещё чего)? 3. Перевод числа в строку в Делфи и обратно в СУБД значительно влияет на время? Или мелочь, в сравнении с чем-то другим? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 14:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич1. Банальный вопрос: как очистить файл БД? Удаляй файл, пересоздавай базу. Андрей ИгоревичЧерез процедуру в IBE массив в 500к значений заполняется единицами за 580 секунд, через прямую SQL команду за 500 секунд: Это из-за транзакций. Их стоит дергать чуть реже. Например на каждые 10 тыс строк. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 14:54 |
|
||


|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Вынеси transaction.starttransaction и transaction.commit за пределы циклов. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 14:56 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Если база для тебя - нечто "промежуточное", можно отключить "forced writes". ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 15:01 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Ну и используй параметры. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. PS: может и не заработать: с IBX я давно не работал.Но идея, надеюсь, понятна. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 15:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Да, и вместо TIBQuery используй TIBSQL. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 15:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
wadmanАндрей Игоревич1. Банальный вопрос: как очистить файл БД? Удаляй файл, пересоздавай базу. А если не пересоздавать базу, а очищать значения, база так и будет неконтролируемо расти или остановится на некотором объеме? чччДВынеси transaction.starttransaction и transaction.commit за пределы циклов. Помогло, время заполнения уменьшилось до 90 секунд. чччДЕсли база для тебя - нечто "промежуточное", можно отключить "forced writes". А что это поменяет? В плане что это параметр регулирует? чччДНу и используй параметры. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. Подправил на код Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. чччДДа, и вместо TIBQuery используй TIBSQL. А вот это особо не помогло, время почти не изменилось (с 31 до 30 сек, в порядке погрешности). В общем уже намного лучше в 20 раз, но всё равно многовато... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:29 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Используй под файл базы быстрый накопитель SSD. Можно вообще на виртуальном (который в оперативной памяти) диске базу разместить. Спросить совета у товарищей здесь: http://www.sql.ru/forum/interbase ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:34 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Возможно, тебе просто типизированный файл подойдет. Непонятна твоя задача ибо. Когда абстрактно "нужно много и быстро" - так чаще всего не получится. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:37 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, от ахулиарда ParamByName тоже хорошо бы избавиться вынеся выдергивание параметров за цикл ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
да и батчами по уму надо вставлять а не по одной записи, но это не каждый дак пожалуй сумеет ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:40 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavanАндрей Игоревич, от ахулиарда ParamByName тоже хорошо бы избавиться вынеся выдергивание параметров за цикл +1 Создай объекты - параметры заранее: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. А потом перед каждым выполнением ExecSQL обращайся к ним: Код: pascal 1. 2. 3. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:46 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavanда и батчами по уму надо вставлять а не по одной записи, но это не каждый дак пожалуй сумеет IBX вряд ли такое может. :) FIB+ так делает, используя ExecuteBlock... ну, можно руками. ........ Тут непонятно, что в итоге ТС хочет получить. Залить данные он может и зальет, но вот обратно - как получать думает? Эмулятор многомерного массива? Будет ли структура пригодной для быстрого доступа? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:49 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичА если не пересоздавать базу, а очищать значения, база так и будет неконтролируемо расти или остановится на некотором объеме? База расти не будет. Более того, ходят слухи, что повторная запись в уже созданный ранее (о "очищенный") файл будет быстрее, чем в новый. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 16:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
06.02.2018 14:51, Андрей Игоревич пишет: > 1. Какие вообще БД можно использовать без поднятия сервера для указанных > выше задач (массивы с 10кккк значений)? Никакие. Любая серьёзная СУБД - это сервер. > одним фалом типа .ддл? Просто на основном рабочем компьютере абсолютный > минимум прав, а дергать админа ради установки сервера., ну такое. Ничего, пусть потрудится или даст тебе админские права. > 1. Банальный вопрос: как очистить файл БД? Это не "банальный вопрос", а до тошноты затрахавший баян. В общем случае - выгрузкой/загрузкой. Но этого делать не нужно. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 17:04 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДИспользуй под файл базы быстрый накопитель SSD. Можно вообще на виртуальном (который в оперативной памяти) диске базу разместить. Спросить совета у товарищей здесь: http://www.sql.ru/forum/interbase На данный момент и так на весьма быстром SSD (M2) всё крутится, варианты с оперативной памятью можно и без БД сделать :), для отдельных задач так и делаю. чччД Возможно, тебе просто типизированный файл подойдет. Непонятна твоя задача ибо. Когда абстрактно "нужно много и быстро" - так чаще всего не получится. Как раз типизированными файлами сейчас и реализовано. Но стандартные "File of record" больше двух гигов (NTFS, если что) тоже вылетают с ошибкой (вне зависимости от числа записей,надо разбираться, отложил на "после освоения варианта с БД"), либо делать кучу файлов. vavanАндрей Игоревич, от ахулиарда ParamByName тоже хорошо бы избавиться вынеся выдергивание параметров за цикл А как? Что-то не соображу. понял, спасибо. vavanда и батчами по уму надо вставлять а не по одной записи, но это не каждый дак пожалуй сумеет Я так понимаю, тут что-то на тему пакетной записи/транзакций? Где в одно действие добавляется много строк? чччДvavanАндрей Игоревич, от ахулиарда ParamByName тоже хорошо бы избавиться вынеся выдергивание параметров за цикл +1 Создай объекты - параметры заранее: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. А потом перед каждым выполнением ExecSQL обращайся к ним: Код: pascal 1. 2. 3. Ни на что не повлияло, время даже возросло, но незначительно, около 35 секунд. чччДТут непонятно, что в итоге ТС хочет получить. Залить данные он может и зальет, но вот обратно - как получать думает? Эмулятор многомерного массива? Будет ли структура пригодной для быстрого доступа? Проблемы надо решать по мере поступления :), для начала надо хоть БД заполнить :). А вообще, если запрос к одиночной строке будет достаточно быстрым (измерятся в миллисекундах, а не в секундах), то меня уже устроит, в программе заранее будет производится нужная математика, а с БД нудно будет выцеплять значения по индексам, при том не слишком много за раз, до 100к. Задачи сразу над всем массивом данных я сейчас реализую в процессе считывания (результаты проще сохранить, нежели исходные данные). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 17:05 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Dim200006.02.2018 14:51, Андрей Игоревич пишет: > 1. Какие вообще БД можно использовать без поднятия сервера для указанных > выше задач (массивы с 10кккк значений)? Никакие. Любая серьёзная СУБД - это сервер. > одним фалом типа .ддл? Просто на основном рабочем компьютере абсолютный > минимум прав, а дергать админа ради установки сервера., ну такое. Ничего, пусть потрудится или даст тебе админские права. > 1. Банальный вопрос: как очистить файл БД? Это не "банальный вопрос", а до тошноты затрахавший баян. В общем случае - выгрузкой/загрузкой. Но этого делать не нужно. У меня сейчас на компе стоят конечноэлементные расчетные комплексы, которые работают даже с 100кккк значений, и как я понимаю там тоже реализовано по средством БД, хоть и собственной. Ну про удаление уже почитал в других темах, и "горение" некоторых по этому вопросу тоже уже увидел. :). Если не будет расти, пусть живет. Вариант с админом для моего компа не критичен, просто тогда на любом другом компе, где надо запустить программу нужно запускать сервер, либо организовывать связь с моим компом. Можно, конечно, но как-то слишком много действий ненужных для задачи. Проще уж типизированные файлы использовать в большом количестве, или вообще самому написать код для сохранения, поиска и извлечения данных из файла (начинаю подумывать о таком варианте, но пугают возможные трудности). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 17:13 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичЯ так понимаю, тут что-то на тему пакетной записи/транзакций? Где в одно действие добавляется много строк?все верно. это способно дико ускорить вставку Андрей ИгоревичНи на что не повлияло, время даже возрослоа как уж щаз код выглядит? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 17:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavanАндрей ИгоревичЯ так понимаю, тут что-то на тему пакетной записи/транзакций? Где в одно действие добавляется много строк?все верно. это способно дико ускорить вставку Андрей ИгоревичНи на что не повлияло, время даже возрослоа как уж щаз код выглядит? Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. Правда сейчас я уже дома, тут firebirdа нету, да и ссылки на БД надо править, так что правки смогу сделать только завтра (лень дома всё настраивать, хотя...). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 18:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичВариант с админом для моего компа не критичен, просто тогда на любом другом компе, где надо запустить программу нужно запускать сервер, либо организовывать связь с моим компом. Можно, конечно, но как-то слишком много действий ненужных для задачи. В этом месте вас ввели в заблуждение, - FB прекрасно работает в однопользовательском локальном встраиваемом режиме, правда для использования данной возможности необходима патченная IBX либо что-то из более современно-функциональных компонентов доступа. Тот же FireDAC, например, если выбирать из штатной поставки. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:24 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoft777... необходима патченная IBX... ? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:28 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Для того чтобы указать ей нужную VendorLibrary. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:32 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoft777Андрей ИгоревичВариант с админом для моего компа не критичен, просто тогда на любом другом компе, где надо запустить программу нужно запускать сервер, либо организовывать связь с моим компом. Можно, конечно, но как-то слишком много действий ненужных для задачи. В этом месте вас ввели в заблуждение, - FB прекрасно работает в однопользовательском локальном встраиваемом режиме, правда для использования данной возможности необходима патченная IBX либо что-то из более современно-функциональных компонентов доступа. Тот же FireDAC, например, если выбирать из штатной поставки. Не суть, важно то, что к каждому компу придется просить админку или просить админа ставить то, что мне нужно, а я работаю в очень бюрократизированной организации, как бы ещё служебки не заставили писать с разъяснением что я хочу установить, зачем, имею ли я на это лицензию, точно ли это опенсорс (а это точно он?). Нафиг весь это геморой, с учётом того, что данное решение уже выглядит как костыль. На данный момент я программирую всё на своем компе, чтоб избежать всего этого ада, а потом просто копирую экзешник (благо хоть на них права не порезали) на рабочий комп. П.С. Не стоит забывать, что лицензии на Делфи у меня тоже нет :). П.С. В теории можно даже Делфи запросить и купить и много чего можно, но никто в здравом уме никогда не тронет бюрократического монстра без веской причине, он просто "съест" такого инициативного. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:34 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoftчччД, Для того чтобы указать ей нужную VendorLibrary. Что есть "VendorLibrary" и для чего нужно патчить IBX при работе FB в однопользовательском локальном встраиваемом режиме,и отчего это "встраиваемый режим" должен быть "однопользовательским"? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:37 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, Я же об этом вам и толкую. Копируете экзешник, а с ним ещё вложенный каталог со "встраиваемым" FB. И все, если вас устраивает изолированный локальный режим типа чисто для расчетов. По крайней мере запомните, что есть такая удобная штатная возможность. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:41 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Патамучта в состоянии искаропки эта окаменелость с FB в режиме Embedded Server работать почему-то не желает. Вы погодите забрасывать новыми вопросами, поищите.по форуму, - буквально в прошлом году этот вопрос снова всплывал и один из участников приводил свой вариант возможного патча. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:48 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
а че, ParamByIndex в IBX нема? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
fd00ch, Их есть у него. Но предложенный выше вариант обращения сразу по сохранённым указателям все равно д.б. Самым быстрым. Т.е. В этом случае вообще ничего не искать.)) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
и, да, я бы выбрал SQLite для мелких однопользовательских задач. если лицензионность индифферентна, то DISQLite для доступа. там, кстати, есть демка с генерацией БД (text+text+int+float+float+float+float+float+float), на моем среднем компе скорость 200к/сек строк генерации рандомных данных и вставки их в новую базу на SSD. но при прямых руках таких скоростей и с Firebird достичь можно ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 20:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Как-то делал массовую вставку примитивных по структуре записей в библиотеке UIB Как ни противно было признаваться - сделать в памяти текстовый скрипт из мнооооожества строк INSERT .... VALUES( ... ) и скормить его Firebird'y оказалось заметно быстрее, чем препарированная кверь в цикле с изменением параметров (ParamByName не использовался, параметры заполнялись по номеру). Такие дела.... Андрей ИгоревичКак раз типизированными файлами сейчас и реализовано Ну и хорошо, зачем их обязательно внутрь SQL засасывать, они от этого только больше в размере станут. Но если очень хочется - почитай про EXTERNAL TABLE - возможно задачу распарсить файл - если тструктура действительно простая и однородная - можно будет переложить на сам Firebird INSERT INTO REAL_TABLE(.....) SELECT * FROM EXTERNAL_TABLE А вообще я бы тебе советовал перейти в форум про Firebird, описать задачу, объёмы данных ,как част ои какмного пишете читаете, и возможно тебе просто скажут, что SQL не для того. PS. насчет транзакций.... Ну вообще-то вызывать транзакции слишком часто ( или наоборот слишком редко, но это в меньшей степени ) - это азбучный способ затормозить сервер. http://www.ibase.ru/dontdoit/ http://www.ibase.ru/45-ways-to-improve-firebird-performance-russian/ ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
fd00ch, если новое начинать - то лучше mORMot - можно начать с SQLite ,а если не понравистя (данных слишком много, например, то переключиться в не-SQL плоские файлы Кстати, был ещё NexusDB - табличные файлы со встроенным SQL-языком написанные целиком на Delphi Но насколько это надёжно - мнения были разные. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoft...Патамучта в состоянии искаропки эта окаменелость с FB в режиме Embedded Server работать почему-то не желает ... и один из участников приводил свой вариант возможного патча. VDSoft...поищите.по форуму... Ты придумал, а мне искать? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:05 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Покажешь класс подключения/работы непатченного IBX с Embedded FB Server и можешь твёрдо рассчитывать на мои извинения. В противном случае рассчитываю на них уже с вашей стороны.. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoftчччД, Покажешь класс подключения/работы непатченного IBX с Embedded FB Server и можешь твёрдо рассчитывать на мои извинения. В противном случае рассчитываю на них уже с вашей стороны.. "А слабо Вольдемару в бассейн нырнуть?" - (с). У меня работает. Если у тебя проблемы - спрашивай, не стесняйся. Только конкретные вопросы задавай. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:22 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Ну работает и работает, может научите кого, если попросят. У меня тож работает в частном патче IBX. А вопросов, если заметите, я не имел уже с самого начала и не могу понять этого вашего упорного выпрыгивания из штанов. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:43 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Что-то всего по написали, половину я не понял (о чем спорили вообще не понял). Вы лучше по поводу оптимизации этого 21170870 кода подскажите :), если в хотя бы 3-10 раз его ускорить, то уже норм будет. Ну там сразу по 5 команд одной строкой выполнять или ещё чего. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 21:59 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич...если в хотя бы 3-10 раз его ускорить, то уже норм будет. Ну там сразу по 5 команд одной строкой выполнять или ещё чего. Вместо "Insert into" пишешь "Execute block". За одно обращение задаешь кучу значение параметров, для нескольких Insert: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 22:12 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Я странной мыслью поделюсь - а может куски этих больших массивов в blob-ах хранить? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 22:55 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir BaskakovЯ странной мыслью поделюсь - а может куски этих больших массивов в blob-ах хранить? Тогда и СУБД никакая не нужна - типизированный файл и все. ТС хочет доступ по индексам массива. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.02.2018, 23:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичКак раз типизированными файлами сейчас и реализовано. Но стандартные "File of record" больше двух гигов (NTFS, если что) тоже вылетают с ошибкой... Это наверняка решается одной строкой. Покажи код, сразу ошибка найдется. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 01:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДVladimir BaskakovЯ странной мыслью поделюсь - а может куски этих больших массивов в blob-ах хранить? Тогда и СУБД никакая не нужна - типизированный файл и все. ТС хочет доступ по индексам массива. По индексу можно находить большой кусок данных..... а не одно число. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 06:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичЧто-то всего по написали, половину я не понял (о чем спорили вообще не понял). Вы лучше по поводу оптимизации этого 21170870 кода подскажите :), если в хотя бы 3-10 раз его ускорить, то уже норм будет. Ну там сразу по 5 команд одной строкой выполнять или ещё чего. Попробуйте разделить исходные данные на 2-3 части, и запускать несколько клиентских приложений с разных компов, или на крайний случай с одного, для заполнения одной и той же БД. Если затычка в предварительной подготовке данных в клиентском приложении, и сервер сейчас "простаивает", то при таком подходе может получиться быстрее (скажем загрузить больше ядер/потоков компюьтера). Обрамление транзакций start/commit, должно быть через примерно 10000-20000 инсертов. То есть не на каждый инсерт, но и миллион инсертов за одну транзакцию тоже не рекомендуют. Разрабатывать (и заполнять БД) можно на сервере на своем компе, а если переносить на другой комп для работы, можно пользоваться embedded версией firebird. там не сервер, а просто копирование нескольких файлов. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 12:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Vladimir BaskakovЯ странной мыслью поделюсь - а может куски этих больших массивов в blob-ах хранить?не надо ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 12:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
VDSoftпредложенный выше вариант обращения сразу по сохранённым указателям все равно д.б. Самым быстрымя вообще не понял как оно у него стало медленнее parambyname возможно внешние тормоза так круто перекрыли ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavan, может, он тест запускал параллельно с просмотром видео. Или однократно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДАндрей Игоревич...если в хотя бы 3-10 раз его ускорить, то уже норм будет. Ну там сразу по 5 команд одной строкой выполнять или ещё чего. Вместо "Insert into" пишешь "Execute block". За одно обращение задаешь кучу значение параметров, для нескольких Insert: код образец Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. Попробовал данный вариант, ничего не получилось :). Вообще код выглядит ужасно, мой чувство прекрасного горько плачет. мой код Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99.  Но "вообще" данный вариант мне чисто эстетически что-то не очень :). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:44 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Ты в IBEpert сей EB испытывал? Начни с него, с одного insert, потом добавляй. Может, в ibx глюк. А может, в FB. А может, в твоём коде. Искать надо. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:51 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДАндрей ИгоревичКак раз типизированными файлами сейчас и реализовано. Но стандартные "File of record" больше двух гигов (NTFS, если что) тоже вылетают с ошибкой... Это наверняка решается одной строкой. Покажи код, сразу ошибка найдется. Может быть, надо только код заново написать, яж его подкастылил :). Сейчас попробую. S.G.Андрей Игоревич... Попробуйте разделить исходные данные на 2-3 части, и запускать несколько клиентских приложений с разных компов, или на крайний случай с одного, для заполнения одной и той же БД. Если затычка в предварительной подготовке данных в клиентском приложении, и сервер сейчас "простаивает", то при таком подходе может получиться быстрее (скажем загрузить больше ядер/потоков компюьтера). Обрамление транзакций start/commit, должно быть через примерно 10000-20000 инсертов. То есть не на каждый инсерт, но и миллион инсертов за одну транзакцию тоже не рекомендуют. Разрабатывать (и заполнять БД) можно на сервере на своем компе, а если переносить на другой комп для работы, можно пользоваться embedded версией firebird. там не сервер, а просто копирование нескольких файлов. Ну в контексте данной задачи, это уже не костыль, это целая инвалидная коляска. А многозадачность в виде нескольких потоков в одном приложении чтоль не работает с БД? Но в распаралеливании есть сложность придумывания алгоритма распаралеливания (тавтология блин), мнеж в итоге не единицами надо всё заполнять, и по факту размеры массивов не известны, указанный в самом начале - максимально возможный вариант. Если в несколько потоков работать с БД можно, то попробую. Обрамление транзакций start/commit - в принципе сработало даже на 20ккк значений при расположении перед и после цикла, но думаю закину счетчик и "обрамление" буду выполнять раз в 10к инсертов, не сложно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:54 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavanVDSoftпредложенный выше вариант обращения сразу по сохранённым указателям все равно д.б. Самым быстрымя вообще не понял как оно у него стало медленнее parambyname возможно внешние тормоза так круто перекрыли Ну яж написал - в порядке погрешности. У меня вон сейчас заполнение, случайно запущенное за 20 сек выполнилось, хотя вчера за 30 было. Может ССДшник тупит, может кешь у ССДшника кончился (у М2 там как-то хитро, есть супербыстрый кеш, есть остальная память помедленней), может процесс какой решил не делится процессорной мощностью. Просто заметного прироста не заметил. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 13:58 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДТы в IBEpert сей EB испытывал? Начни с него, с одного insert, потом добавляй. Может, в ibx глюк. А может, в FB. А может, в твоём коде. Искать надо. В ИБ не пробовал, я не очень понимаю синтаксис [(<inparams>)] этого, точнее этого: Код: plsql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. В мануале всякие не очень понятные примеры Код: plsql 1. 2. Надо, видимо, глубже закапываться. Количество инсертов влияет только на цифру после "сдвига" (offset). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 14:09 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
не очень понимаю синтаксис [(<inparams>)]> - внешние имена, внутренние имена... :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 14:14 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич Код: pascal 1. ой, ё.... я надеюсь, рядом с реалдьными ВВЭРами этой программы не будет... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 14:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch, а в чем проблема? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 14:44 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, 1) в уровне подготовки, вплоть до того, что ТС настоячиво спрашивает азы по FB в форуме по Delphi 2) в требованиях к надежности и скорости управления ядерными реакторами ( привет внезапной сборке мусора в FB например) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 14:54 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochчччД, 1) в уровне подготовки, вплоть до того, что ТС настоячиво спрашивает азы по FB в форуме по Delphi 2) в требованиях к надежности и скорости управления ядерными реакторами ( привет внезапной сборке мусора в FB например) Помимо управления ректором, есть ещё просто колоссальное количество этапов разработки и конструирования. Значительная часть которых связана с расчетами. Даже так - разработка тех проекта куда более сложный и долгий процесс (про цену точно не скажу, но, сопоставимо), чем само строительство реактора. И управление реактором разрабатывают уже профессиональные программисты (коим я ни разу не являюсь) и совсем иначе, по другим принципам. В общем это совершенно разные люди с разным образованием (хотя возможны пересечения). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 15:06 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
1. При необходимости хранить и обрабатывать гигабайты данных таки желателен программист Хотя бы потому что незамеченное случайнео искажение данных может привести к некорректному результату, о чем никто не узнает, пока новый продвинутый план кампании на практике не окажется хуже старых дубовых, например. 2. Я сильно сомневаюсь, что для хранение гигабайтов однородных данных, без необходимости автоматически отслеживать сложную "ссылочную целостность / referential integrity", SQL вообще правильный инструмент. 2а. Часто SQL используют для удобства, не глядя на ухудшение скорости. Например хранение настроек программы в SQLite и аналогично. Это удобно. А потери в скорости и дисковом пространстве незаметны и их справедливо игнорируют. 2б. Хранение однородных данных в SQL с "обвязкой" в виде дополнительной информацией вполне вероятно увеличит общий размер файлов. 2в. Может казаться соблазнительным использовать SQL дял расчетных задач. Вместо ручного написания циклов, бегающих по миллионам записей - пишем один UPDATE и он все "делает сам". Я так экспериментировал с Firebird, и решил такого не повторять. Как тоьлко начинаются какие-то ошибки, типа слишком малое значение округляется в ноль, лезут ошибки вычисления и понять где именно на каких конкретно данных я чего=-то не учёл и словил "деление на ноль" становится очень сложно. Удобство "одного UPDATE'а" мгновенно компенсируется ужасом поиска и исправления ошибок, если что-то идёт не так. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 15:39 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch1. При необходимости хранить и обрабатывать гигабайты данных таки желателен программист Хотя бы потому что незамеченное случайнео искажение данных может привести к некорректному результату, о чем никто не узнает, пока новый продвинутый план кампании на практике не окажется хуже старых дубовых, например. 2. Я сильно сомневаюсь, что для хранение гигабайтов однородных данных, без необходимости автоматически отслеживать сложную "ссылочную целостность / referential integrity", SQL вообще правильный инструмент. 2а. Часто SQL используют для удобства, не глядя на ухудшение скорости. Например хранение настроек программы в SQLite и аналогично. Это удобно. А потери в скорости и дисковом пространстве незаметны и их справедливо игнорируют. 2б. Хранение однородных данных в SQL с "обвязкой" в виде дополнительной информацией вполне вероятно увеличит общий размер файлов. 2в. Может казаться соблазнительным использовать SQL дял расчетных задач. Вместо ручного написания циклов, бегающих по миллионам записей - пишем один UPDATE и он все "делает сам". Я так экспериментировал с Firebird, и решил такого не повторять. Как тоьлко начинаются какие-то ошибки, типа слишком малое значение округляется в ноль, лезут ошибки вычисления и понять где именно на каких конкретно данных я чего=-то не учёл и словил "деление на ноль" становится очень сложно. Удобство "одного UPDATE'а" мгновенно компенсируется ужасом поиска и исправления ошибок, если что-то идёт не так. Желателен, знаешь сколько будет стоить профессиональный программист с фундаментальными знаниями в прочности, нейтронной физике, конструкции РУ? Да и ещё и только на время решения конкретной задачи. SQL мне тут насоветовали в огромных количествах, на данный момент я уже и сам разочаровался в этом методе, просто пытаюсь уж до конца реализовать, что был как вариант. Данные(значение полей) я планировал в БД хранить как строку типа "2.08406E+13", а в дальнейшем работать просто с данными через запросы по индексам, не думаю, что это может привести к каким-то ошибкам. Как тут уже писалось, БД начал использовать из-за очень большого объема значений (до 10кккк), для которого не хватало оперативной памяти и возникли проблемы при прокручивании такого объема массивов (при том мне для большей части задач весь массив нужен не был). Были варианты через типизированные файлы, на данный момент через них и сделал. Но не всё меня устраивало, решил попробовать БД. Сейчас добью и опять вернусь к типизированным файлам. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 15:52 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДТы в IBEpert сей EB испытывал? Начни с него, с одного insert, потом добавляй. Может, в ibx глюк. А может, в FB. А может, в твоём коде. Искать надо. В общем в IB работает, почему не работает через Делфи - разбираться что-то не хочется. Фиг с ним,с этим способом. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 16:08 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochКак тоьлко начинаются какие-то ошибки, типа слишком малое значение округляется в ноль, лезут ошибки вычисления и понять где именно на каких конкретно данных я чего=-то не учёл и словил "деление на ноль" становится очень сложно. Удобство "одного UPDATE'а" мгновенно компенсируется ужасом поиска и исправления ошибок, если что-то идёт не так Объясни, чем дельфёвое "division by zero" удобнее, чем ошибка с кодом на тему "division by zero" от SQL-сервера (касательно FB - это isc_exception_float_divide_by_zero)? Как раз наоборот - чтобы найти проблемную запись, достаточно сделать простейший запрос с фильтром по полю, на которое происходит деление. А чтобы обеспечить себе отсутствие такой проблемы - достаточно добавить в исходный UPDATE элементарное дополнительное условие в WHERE или, что обычно лучше, значение для обновляемого поля при нулевом делителе через CASE. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 16:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич... В общем в IB работает, почему не работает через Делфи - разбираться что-то не хочется. Фиг с ним,с этим способом. Возможно, дело в старых IBX. Ну, как хочешь. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 16:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockпри нулевом делителе через CASE или при "близком к нулю", как ты написал в примере. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 16:14 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Иии при достижении размера базы в 2.133.901.312 байт начались проблемы (примерно на таком же размере, кстати, начинались проблемы с типизированными файлами). Добавляет некоторое количество данных и выпадает с ошибкой добавления нового значения (база перед добавлением значений была очищена), создал рядом новую базу и тем же кодом спокойно ей заполнил. Может это виндовские заморочки? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 16:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockОбъясни, чем дельфёвое "division by zero" удобнее, чем ошибка с кодом на тему "division by zero" от SQL-сервера Когда на сотне тысяч строк с разными столбцами такое встречается в Delphi - я попадаю внутрь среды в середину цикла, где вижу все промежуточные посчитанные значения. Как минимум вижу значение счётчика цикла. Даже если такое происходит у клиента и удалённая отладка не возможна - я могу туда вставить логирование. В случае Firebird я получаю rollback с потерей ВСЕХ промежуточных вычислений. Остаются только исходные данные. На которых ГДЕ-ТО одна из вычислительных формул выдает ошибку. Можно, конечно, написать EXECUTE BLOCK с циклом по всем строкам и UPDATE ... WHERE CURRENT OF и перехватом ошибок.... В общем, проимитировать цикл Delphi средствами PSQL И все равно остаться без отладочной среды. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:04 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич, файловая система какая на диске, где лежат файлы с данными ? не FAT32 случайно ? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:04 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochАндрей Игоревич, файловая система какая на диске, где лежат файлы с данными ? не FAT32 случайно ? Нет - NTFS. В общем завтра поковыряюсь, сегодня рабочий день катится к концу. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:11 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичДанные(значение полей) я планировал в БД хранить как строку типа "2.08406E+13" зачем, если в SQL есть "родной" тип DOUBLE PRECISION ? конечно, если точности стандартных типов не хватает и нужны гораздо более длинные числа с плавающей запятой, чем поддерживает стандартный процессор (и стандартная Delphi), тогда только текстом и имитировать "вычисления в столбик" (библиотеки типа big number). но если вычислительная часть у вас сделана на стандартном типе double, то это лишнее ------------- Андрей Игоревичпрофессиональный программист с фундаментальными знаниями в прочности, нейтронной физике, конструкции РУ А что, работа командой уже не в моде, всё должен один единственный Левша-многостаночник сделать? В принципе, конечно, компьютеры не обязательны, при расчете РБМК от численного моделирования отказались принципиально, но и результат не самый лучший. Андрей ИгоревичБыли варианты через типизированные файлы, на данный момент через них и сделал. 1) Тут могут быть проблемы в скорости, поскольку писались эти типизированные файлы оооочень давно, когда памяти в компьютерах было мало. Буферизация там крохотная. Лучше бы найти что-нибуд ьс буферизующим чтением-записью. Например тут один товарищ выложил свою библиотеку CachedBuffers, но насколько она надежна и крута не знаю, не пользовался. 2) В любом случае на таких объёмах возможны случайные повреждения данных. Пролетела частица, переключила пару бит, число поменялось, никто не заметил. В типизированых файлах желательно кроме самих данных добавлять информацию для детектирования и, по возможности, исправления повреждённых данных. Можете, конечно, сказать что у вас настолько много сырых данных, что случайные изменения в паре десятков чисел ни на что не повлияют, может быть так и есть. 3) для потоковой обработки больших объямов данных возможно стоит купить два отдельных жёстких диска. С первого файлы читаем, выполняем вычисления, на второй диск пишем. Если вычисления идут в несколько этапов, и каждый этап кладется в файл, то делаем по очереди ,с 1-го диска на 2-1, потом со 2-го на первый и так далее. Цель - перевести аппаратуру дисков из режима случайного доступа в режим потоковой работы, который быстрее. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
TFileStream в современных Delphi работаетс 64-битными размерами файлов. А вот старые паскалевского типа типизированные файлы скорее всего никто не обновлял, и там действительно реализация сделана через 32-битные числа, с учётом знакопеременности - надежная работа только до 2^31 - примерно на 2 миллиарда байтов и выходите ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:23 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochАндрей ИгоревичДанные(значение полей) я планировал в БД хранить как строку типа "2.08406E+13" зачем, если в SQL есть "родной" тип DOUBLE PRECISION ? конечно, если точности стандартных типов не хватает и нужны гораздо более длинные числа с плавающей запятой, чем поддерживает стандартный процессор (и стандартная Delphi), тогда только текстом и имитировать "вычисления в столбик" (библиотеки типа big number). но если вычислительная часть у вас сделана на стандартном типе double, то это лишнее ------------- Андрей Игоревичпрофессиональный программист с фундаментальными знаниями в прочности, нейтронной физике, конструкции РУ А что, работа командой уже не в моде, всё должен один единственный Левша-многостаночник сделать? В принципе, конечно, компьютеры не обязательны, при расчете РБМК от численного моделирования отказались принципиально, но и результат не самый лучший. Андрей ИгоревичБыли варианты через типизированные файлы, на данный момент через них и сделал. 1) Тут могут быть проблемы в скорости, поскольку писались эти типизированные файлы оооочень давно, когда памяти в компьютерах было мало. Буферизация там крохотная. Лучше бы найти что-нибуд ьс буферизующим чтением-записью. Например тут один товарищ выложил свою библиотеку CachedBuffers, но насколько она надежна и крута не знаю, не пользовался. 2) В любом случае на таких объёмах возможны случайные повреждения данных. Пролетела частица, переключила пару бит, число поменялось, никто не заметил. В типизированых файлах желательно кроме самих данных добавлять информацию для детектирования и, по возможности, исправления повреждённых данных. Можете, конечно, сказать что у вас настолько много сырых данных, что случайные изменения в паре десятков чисел ни на что не повлияют, может быть так и есть. 3) для потоковой обработки больших объямов данных возможно стоит купить два отдельных жёстких диска. С первого файлы читаем, выполняем вычисления, на второй диск пишем. Если вычисления идут в несколько этапов, и каждый этап кладется в файл, то делаем по очереди ,с 1-го диска на 2-1, потом со 2-го на первый и так далее. Цель - перевести аппаратуру дисков из режима случайного доступа в режим потоковой работы, который быстрее. Можно и в Double, сейчас глянув как распухает файл БД, может лучше и Double, всё таки строка в 11 символов - 22 байта, против 8. Работа в команде это хорошо, но по факту вместо одного человека нужно уже два. Скажем так, пока я делаю программы "для себя", для визуализации и обработки исходных данных и результатов расчетов аттестованных программ (которые, данным"бонусами" в большинстве своем не обладают). Но это пока, а там посмотрим. 1. Найти - это хорошо, но сложно :). 2. По поводу повреждения данных, я в условиях нейтронного облучения не работаю :), повреждение данных в обычных условиях кажется мне маловероятным, да и современные носители информации, думаю, имеют всякие там суммы и прочие данные для восстановления битых секторов. 3. В таком случае проще купить больше оперативной памяти и гонять вообще всё в ней, но это "фантастика" для бюрократизированной организации. Есть ВоркСтешен - на ней и работайте. Даже суперкомпьютер есть, просто мороки для его использования слишком много. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:35 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochВ случае Firebird я получаю rollback с потерей ВСЕХ промежуточных вычислений. Остаются только исходные данные. А когда в цикле на клиенте - что, кусочки какие-то коммитятся, что ли? И это ты считаешь правильным? И, кстати, отменятся только изменения, которые внесены текущим UPDATE-ом, который упал. Принимать решение commit или rollback предыдущих успешных изменений, сделанных в этой транзакции, всё равно придется клиенту. AriochНа которых ГДЕ-ТО одна из вычислительных формул выдает ошибку. не ГДЕ-ТО, а YuRockчтобы найти проблемную запись, достаточно сделать простейший запрос с фильтром по полю, на которое происходит деление ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:44 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич1. Найти - это хорошо, но сложно :). Это легко. http://www.sql.ru/forum/afsearch.aspx?s=cachedbuffers&submit=?????&bid=20 Сложно - оценить надежность и выигрыш в скорости в вашем случае. Стоит ли овчинка выделки и не будет ли с ней хуже ,чем без нее. Андрей Игоревичповреждение данных в обычных условиях кажется мне маловероятным Да, каждой конкретное повреждение маловероятно. Но у вас 2 миллиарда байтов только в одоном файле. Закон больших чисел может вас догнать. Впрочем, если вы не занимаетесь расчётными функциями, а просто визуализируете посчитанное и данное вам другими - то "случайные изменения в паре десятков чисел ни на что не повлияют" Однако вот отслеживать повреждления данных в процессе передачи оттуда, где их считали, к вам - весьма рекомендую. Повреждения файлов при перекачке в сети у меня встречались. Андрей Игоревичсовременные носители информации, думаю, имеют всякие там суммы и прочие данные .....крайне дешевы, на грани самоокупаемости. Со всеми вытекающими для запасов прочности - их мало. а кроме самих дисков - есть ещё межкомпьютерная сеть, есть оперативная память в компьютерах (и у бытовых комьпютеров там никаких ECC близко нет). Хотя если Workstation, то может и быть в принципе. Андрей ИгоревичВ таком случае проще купить больше оперативной памяти и гонять вообще всё в ней Нет. Скорость винчестеров - чистых, не фрагментированных, подготовленных для потоковой работы - порядка 100 МБ/с Пусть у вас очень быстрый и очень новый винчестер и там 150 МБ/с Если же потоковой работы добиться не удастся, то скорость может упасть на порядок. Скорость оперативной памяти - на 2-3 порядка больше. Лень исктаь цифры, кроме того не знаю какая память в вашей рабочей станции. Есть крайне сложные вычислительные задачи, где процессор просто не успевает обработать все данные, которые ему даёт винчестер. Типа сжатия видео в высоком качестве. Но это редко. Обычно всё упрется либо в неумение программы использовать оперативную память для ускорения (привет старым паскалевским типизированным файлам), либо в скорость диска. Если винчестер может передать в секунду в оперативную память например 110 МБ, то больше там "не вырастет", даже есливы купите самую большую и самую быструю память - она просто простаивать будет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:49 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockА когда в цикле на клиенте - что, кусочки какие-то коммитятся, что ли? а если иногда читать ? AriochКогда на сотне тысяч строк с разными столбцами такое встречается в Delphi - я попадаю внутрь среды в середину цикла, где вижу все промежуточные посчитанные значения. Как минимум вижу значение счётчика цикла. Даже если такое происходит у клиента и удалённая отладка не возможна - я могу туда вставить логирование. Расскажи мне, как в случае ошибки в середине многострочного UPDATE я могу в Firebird'e посмотреть какую конкретную строку он сейчас читает и какие конкретные значения у всех выражений в этом UPDATE. Как мне попасть внутрь частично выполненного UPDATE? YuRockдостаточно сделать простейший запрос с фильтром по полю, на которое происходит деление 1) такого поля нет, есть тригонометрические расчёты по данных из нескольких полей. Делится одна тригонометрическая формула на другую. 2) значения ровно ноль нет нигде, вообще нет. А деление на ноль есть. Ввиду конечности разрядности чисел с плавающей точкой. Underflow происходит и число ненудевое превращается в ноль. 3) всего этого, что я тебя растолковываю, ты не знаешь. Ты только видишь, что где-то при UPDATE множества строк и множества столбцов выпало деление на ноль. При том, что нолей в таблице нет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 17:56 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичВ таком случае проще купить больше оперативной памяти и гонять вообще всё в ней Кстати, если у вас отдельная (не интегрированная) видеокарта, то промежуточные данные можно хранить в ней, хотя и не очень удобно. Правда у вас объёмы большие, типовая видеокарта-затычка это один, иногда два гигабайта памяти, из которых к тому же пару сотен МБ заберет себе операционка. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:00 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochРасскажи мне, как в случае ошибки в середине многострочного UPDATE я могу в Firebird'e посмотреть какую конкретную строку он сейчас читает и какие конкретные значения у всех выражений в этом UPDATE. Как мне попасть внутрь частично выполненного UPDATE? Никак. В дебаггере логику править смешно, потому нужны логи. К тому же, на компьютерах клиентов и не бывает отладки. Только логи. В логи можно записать параметры запроса, а затем Ariochзначения ровно ноль нет нигде, вообще нет. А деление на ноль есть сделать запрос с фильтром, когда "тригонометрическая формула" возвращает значение, близкое к нулю. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:20 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochчччД, 1) в уровне подготовки, вплоть до того, что ТС настоячиво спрашивает азы по FB в форуме по Delphi 2) в требованиях к надежности и скорости управления ядерными реакторами ( привет внезапной сборке мусора в FB например) Сам ли всегда носом в блюдечко с молочком с первого раза попадаешь? Человек работает, учится. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревиччччД, Иии при достижении размера базы в 2.133.901.312 байт начались проблемы (примерно на таком же размере, кстати, начинались проблемы с типизированными файлами). Добавляет некоторое количество данных и выпадает с ошибкой добавления нового значения (база перед добавлением значений была очищена), создал рядом новую базу и тем же кодом спокойно ей заполнил. Может это виндовские заморочки? Ну ты бы код показал. Может, и решили бы эти проблемы. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:26 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockсделать запрос с фильтром, когда "тригонометрическая формула" возвращает значение, близкое к нулю. И вообще, если такое возможно и штатно - то значит логика построена неверно - необходимо, я уже писал, устанавливать значение при значении делителя, близком к нулю, и при всех остальных, с помощью CASE, например. Типа такого: Код: sql 1. 2. 3. 4. 5. 6. 7. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:28 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДАндрей ИгоревиччччД, Иии при достижении размера базы в 2.133.901.312 байт начались проблемы (примерно на таком же размере, кстати, начинались проблемы с типизированными файлами). Добавляет некоторое количество данных и выпадает с ошибкой добавления нового значения (база перед добавлением значений была очищена), создал рядом новую базу и тем же кодом спокойно ей заполнил. Может это виндовские заморочки? Ну ты бы код показал. Может, и решили бы эти проблемы. Ну в конце рабочего дня вторая БД, которую решил протестировать на возможность с работой уже бОльших массивов разрасталась до 4GB, так что не знаю, что было с первой базой, хотя надо и новую будет попробовать записать уже разросшуюся, но это уже завтра. В принципе 50ккк значений было записано минут за 15-20, что не так уж и плохо. А, стоп, я же сразу по 2 значения записывал в одну строку, значит формально я записал 100ккк значений. И стоп в 2 раз. А сколько можно столбцов в БД сделать? 350 можно? Никаких подводных камней не будет? Это, как мне кажется, очень так ускорит заполнение. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:37 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockAriochРасскажи мне, как в случае ошибки в середине многострочного UPDATE я могу в Firebird'e посмотреть какую конкретную строку он сейчас читает и какие конкретные значения у всех выражений в этом UPDATE. Как мне попасть внутрь частично выполненного UPDATE? Никак. В дебаггере логику править смешно, потому нужны логи. К тому же, на компьютерах клиентов и не бывает отладки. Только логи. В логи можно записать параметры запроса, а затем Ariochзначения ровно ноль нет нигде, вообще нет. А деление на ноль есть сделать запрос с фильтром, когда "тригонометрическая формула" возвращает значение, близкое к нулю. Никто не говорил, про "править логику". Говорилось про просмотр значений всех и любых переменных В МОМЕНТ ОШИБКИ. Про клиентские компы не будем, бывает там отладка или нет. Допустим мне данные прислали и на рабочей машине воспроизводится. Ещё раз, как мне внутри многострочного UPDATE сделать просмотр всех его столбцов ровно на той строке, где возникло исключение. В Delphi это называется Debug Windows | Evaluate и Debug Windows |Local Variables YuRockкогда "тригонометрическая формула" возвращает значение, близкое к нулю. Они такого не возвращают. Есть несколько формул. Какая-то из них выдает не значение, а ошибку "деление на ноль" на какой-то строке запроса. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:50 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич... И стоп в 2 раз. А сколько можно столбцов в БД сделать? 350 можно? Никаких подводных камней не будет? Это, как мне кажется, очень так ускорит заполнение. Много можно. Видел табличку в 500 полей. Главное, чтобы данных там не более 64кБайт (реально - чуть поменьше) на одну запись набралось. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДСам ли всегда носом в блюдечко с молочком с первого раза попадаешь? Я последние дни невыспатый, приболевший и злой, не отрицаю. Но когда накоплены гигабайты данных - это уже далеко не "первый раз попасть в блюдечко". ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochАндрей Игоревич1. Найти - это хорошо, но сложно :). Это легко. http://www.sql.ru/forum/afsearch.aspx?s=cachedbuffers&submit=?????&bid=20 Сложно - оценить надежность и выигрыш в скорости в вашем случае. Стоит ли овчинка выделки и не будет ли с ней хуже ,чем без нее. Стало ещё сложнее :). AriochАндрей Игоревичповреждение данных в обычных условиях кажется мне маловероятным Да, каждой конкретное повреждение маловероятно. Но у вас 2 миллиарда байтов только в одоном файле. Закон больших чисел может вас догнать. Впрочем, если вы не занимаетесь расчётными функциями, а просто визуализируете посчитанное и данное вам другими - то "случайные изменения в паре десятков чисел ни на что не повлияют" Однако вот отслеживать повреждления данных в процессе передачи оттуда, где их считали, к вам - весьма рекомендую. Повреждения файлов при перекачке в сети у меня встречались. Андрей Игоревичсовременные носители информации, думаю, имеют всякие там суммы и прочие данные .....крайне дешевы, на грани самоокупаемости. Со всеми вытекающими для запасов прочности - их мало. а кроме самих дисков - есть ещё межкомпьютерная сеть, есть оперативная память в компьютерах (и у бытовых комьпютеров там никаких ECC близко нет). Хотя если Workstation, то может и быть в принципе. Ради интереса поинтересуюсь у друга, который как раз работает с программами для АЭС как там всё реализовано на эту тему, но, если честно, первый раз слышу. Так то у меня на компьютере немало расчетных комплексов (аттестованных, с моим кодом не связанных) считается, и о реализации защиты от случайных повреждений данных не слышал, но может и есть что-то, поспрашиваю. AriochАндрей ИгоревичВ таком случае проще купить больше оперативной памяти и гонять вообще всё в ней Нет. Скорость винчестеров - чистых, не фрагментированных, подготовленных для потоковой работы - порядка 100 МБ/с Пусть у вас очень быстрый и очень новый винчестер и там 150 МБ/с Если же потоковой работы добиться не удастся, то скорость может упасть на порядок. Скорость оперативной памяти - на 2-3 порядка больше. Лень исктаь цифры, кроме того не знаю какая память в вашей рабочей станции. Есть крайне сложные вычислительные задачи, где процессор просто не успевает обработать все данные, которые ему даёт винчестер. Типа сжатия видео в высоком качестве. Но это редко. Обычно всё упрется либо в неумение программы использовать оперативную память для ускорения (привет старым паскалевским типизированным файлам), либо в скорость диска. Если винчестер может передать в секунду в оперативную память например 110 МБ, то больше там "не вырастет", даже есливы купите самую большую и самую быструю память - она просто простаивать будет. Ну после загона в память массива в 3гб (поля одной кампании) я ни разу не смог уперется в проблему с доступом к данным. По сути для моих текущих задач скорость работы из оперативной была избыточна. Сейчас должны поставить Воркстейшн с 32 ГБ оперативы (64 не дали, жмоты). Так как 10кккк это теоретический максимум значений, а по факту их в десятки раз меньше, то буду весма массив в оперативу загонять, но это решение только для компов с большим объемом оперативы. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:54 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockYuRockсделать запрос с фильтром, когда "тригонометрическая формула" возвращает значение, близкое к нулю. И вообще, если такое возможно и штатно - то значит логика построена неверно - необходимо, я уже писал, устанавливать значение при значении делителя, близком к нулю, и при всех остальных, с помощью CASE, например. Типа такого: Код: sql 1. 2. 3. 4. 5. 6. 7. Вот-вот-вот. И получаем мы здесь дважды вычисление одного и того же значения, один раз чтобы проверить на underflow, а вторйо раз, чтобы использовать. Счастливое царство копипаста. .....но олько ,а откуда ты взял 0.000001 ? может быть это как раз огромное, большое значение в данном задаче? То есть надо считать обе части формулы и сравнивать не с константой, а с реальным значением. IF ABS( ..... ) < 0.000001*ABS( ...... ) ОК, а если в формуле не одно деленрие, а три - пишем уже ВОСЕМЬ копипастов? А если там кроме деления - корни квадратные, арксинусу с арктангенсами и прочая? В итоге такой фрактал вырастет, что код на Delphi будет проще, понятнее, короче и быстрее. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 18:57 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичИ стоп в 2 раз. А сколько можно столбцов в БД сделать? 350 можно? Никаких подводных камней не будет? Это, как мне кажется, очень так ускорит заполнение. Столбцов должно быть столько, сколько есть разнотипных значений. https://ru.wikipedia.org/wiki/Нормальная_форма https://habrahabr.ru/post/254773/ Если у комнаты есть площадь и есть количество койкомест - то это два разных столбца. А когда у нас есть квартиры 2-комнатные и 5-комнатные, не нужно делать строки из 2х2=4 и 5х2=10 столбцов. А нужно просто завести по одной строке на каждую комнату, а какие комнаты относятся к каким квартирам - хранить в другой таблице. PS. также в многоверсионных серверах, как Firebird, слишком "широкие" строки медленно обновляются. Если вы их один раз записали и болье не трогаете - то это одно. А если периодически меняете то одно поле, то два - то совсем другое. Я вам на прошлой странице ссылки на ibase.ru давал. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:02 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичВ принципе 50ккк значений что такое КуКлуксКлан в этом контексте? Андрей ИгоревичА сколько можно столбцов в БД сделать? 350 можно? https://firebirdsql.org/en/firebird-technical-specifications/ Item Actual for Firebird 2.5 Maximum row size 64 KB Maximum number of columns per table Depends on data types used. (Example: 16,384 INTEGER (4-byte) values per row.) 16384x4 = 64K ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:04 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochЕщё раз, как мне внутри многострочного UPDATE сделать просмотр всех его столбцов ровно на той строке, где возникло исключение Я уже писал, что никак. Внутри у UPDATE это что - "PDAT" разве что? :) Это просто оператор, какие у него могут быть "внутренности" - не должно волновать прикладного программиста, который использует его. AriochДопустим мне данные прислали и на рабочей машине воспроизводится Хорошо, когда так бывает. Только долго и не далеко всегда. Логи гораздо быстрее можно получить разными способами. AriochКакая-то из них выдает не значение, а ошибку "деление на ноль" на какой-то строке запроса. Значит два варианта: 1. Некорректные аргументы функции - тогда еще проще - необходимо проверять корректность этих аргументов в CASE; 2. Глючная функция - тогда её надо исправить. Тут да, придется спец. SQL-блок писать, чтобы определить, какая запись к исключению приводит. Один раз, для исправления функции. Так или иначе, любая функция не должна вызывать никаких исключений на всей области определения . Поэтому, опять же, надо просто проверять на вхождение параметров в эту область определения. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:06 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockЯ уже писал, что никак. и поэтому расчетные задачи на SQL можно жделать только в примитивных случаях, которые и расчётными назват нельзя по сути YuRockЛоги гораздо быстрее можно получить разными способами. не вопрос, как мне получить лог всех столбцов проблемной строки многострочного UPDATE ? несколько сотен тысяч строк до и после проблемной в лог пихать не надо, только строку, на которой ошибка ? YuRockТак или иначе, любая функция не должна вызывать никаких исключений на всей области определения На области определения она и не вызывает. Деление на ноль происходит вне области определения. А вот выход из идеальной математики без нулей в реальный underflow с не-ноль-равен-нулю происходит неожиданно, и хрен найдешь на каких данных. В итоге при малейших проблемах то, что в Delphi ловится за пару минут, на SQL занимает час, а то и несколько (например если запрос отрабатывает долго). Откуда возвращаемся к моему исхдоному тезису, что попытка написать массовую сложную расчетную задачу изано на на SQL в одну простую строку приводит к огромным потерям времени на создание многостраничных запросов с перепроверкой всех результатов и на поиск конкретных данных, которые ошибку породили. Если же ее изначально писать на Дельфи, то процедура будет куда менее элегантной чем однострочный UPDATE и потратить на организацию циклов времени придется, однострочником не обойтись, зато проблема при вычислениях ловится наглядно и удобно. Есть еще какие-то специализированные языки именно для потоковой обработки больших массивов данных, что-то типа R или H, не помню, не изучал. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:15 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич Давай чуть-чуть поболтаем. Можно данные в базу/из базы записывать не по одному элементу, а блоками. К примеру, есть у тебя 4-х мерный массив, каждая размерность шириной в сто тыщ. Если работать с одной плоскостью (100 000 х 100 000), то понадобится всего 10 млн ячеек памяти. Нормально. Если по твоим алгоритмам ты долго работаешь именно в одной плоскости, то работай с памятью, а как перескочишь на другую - сбрасывай этот блок в базу, доставай оттуда новый и работай с ним. Можно сразу несколько блоков хранить в памяти (например, последние из используемые, или самые часто используемые, или как тебе подсказывает твоя логика обработки данных). Как это делать. Можно написать класс-"менеджер", который имитирует работу с многомерной табличкой. Ты ему указываешь координаты данных, а он тебе возвращает их И ради отдельного элемента он базу не лезет, а лезет лишь в случае, когда блока данных этого элемента нет в памяти. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. Как с этим работать. Также, как с массивом. Только его (экземпляр "массива-класса") следует создать: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. Скорость вырастет не в 3-10 раз, а побольше. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Ariochможет быть это как раз огромное, большое значение в данном задаче? Надо проверять на вхождение в область определения. Только и всего. Я 0.00001 как пример привёл. AriochОК, а если в формуле не одно деленрие, а три - пишем уже ВОСЕМЬ копипастов? Их можно не делать. Как и на клиенте. Просто падать будет. AriochА если там кроме деления - корни квадратные, арксинусу с арктангенсами и прочая? В итоге такой фрактал вырастет, что код на Delphi будет проще, понятнее, короче и быстрее. И будет падать точно так же, только на клиенте, которого обновить сложнее, т.к. их обычно больше, чем баз. Ок, хозяин - барин, но для меня как-то странно звучит тезис "Лучше писать логику в делфи, чем в базе, потому, что база может выдавать арифметические исключения" (при том, что эти же арифметические исключения и делфи точно так же выдает). И ловятся такие ошибки, повторяю, элементарным запросом с параметрами из лога. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:18 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochАндрей ИгоревичИ стоп в 2 раз. А сколько можно столбцов в БД сделать? 350 можно? Никаких подводных камней не будет? Это, как мне кажется, очень так ускорит заполнение. Столбцов должно быть столько, сколько есть разнотипных значений. https://ru.wikipedia.org/wiki/Нормальная_форма https://habrahabr.ru/post/254773/ Не ну это просто правила хорошего тона, но мне-то хорошим быть не обязательно. И если "минимальная логическая избыточность" конфликтует с быстродействием, то почему бы не подзабить на неё :), тем более БД всё равно в таком виде выглядит как костыль. В мечтах я думал о динамическом создании миллионов таблиц связанных древовидной иерархией, но отпугивает потенциальная сложность и куча подводных камней, которые непременно всплывут. AriochАндрей ИгоревичВ принципе 50ккк значений что такое КуКлуксКлан в этом контексте? КилоКилоКило значений :), я думал это очевидно. Кстати, я тут походу переборщил с этими Кило, в общем 50 (100) миллионов значений имелось в виду. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:21 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Ariochне вопрос, как мне получить лог всех столбцов проблемной строки многострочного UPDATE ? несколько сотен тысяч строк до и после проблемной в лог пихать не надо, только строку, на которой ошибка ? Очень просто: получить параметры запроса. А "у себя" сделать "развернутый" запрос с этими параметрами - и получить запись. AriochВ итоге при малейших проблемах то, что в Delphi ловится за пару минут, на SQL занимает час. Ок, спорить не хочу. Arioch(например если запрос отрабатывает долго). Ну конечно же, логика в цикле на клиенте быстрее, чем UPDATE на сервере в 30 раз примерно (это я из "пару минут" и "час" вычислил). AriochОткуда возвращаемся к моему исхдоному тезису, что попытка написать массовую сложную расчетную задачу изано на на SQL в одну простую строку приводит к огромным потерям времени Ок, спорить не хочу. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockи делфи точно так же выдает не точно также, а гораздо лучше -0 она позволяет посмотреть значения любых переменных В МОМЕНТ ОШИБКИ и позволяет записал а лог значения выбранны хпеременных В МОМЕНТ ОШИБКИ YuRockэлементарным запросом с параметрами из лога. Третий раз спрашиваю: как записать в LOG значения столбцов одной единственной строки из миллионострочного UPDATE, только той где произошла ошибка и никаких других ? YuRockИ будет падать точно так же, только на клиенте, которого обновить сложнее Прежде чем обновлять программу - нужно решить проблему. Прежде чем решить проблемУ, надо понять гдеи почему она возникает. Этот шаг в математических расчётных задачах на SQL сделать на порядки дольше и сложнее. PS. даже если ты напишешь мега-навороченный запрос, то вполне вероятно что этот запрос тоже буде тв твоём клиенте, так что все равно придется клиента обновлять ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:36 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
YuRockА "у себя" сделать "развернутый" запрос с этими параметрами - и получить запись. ?????? YuRockНу конечно же, логика в цикле на клиенте быстрее, чем UPDATE на сервере нет, дольше, но зато она запускается ОДИН раз а вот модифицировать запрос пытаясь нащупать где же и почему он падает - придётся много раз ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДИ ради отдельного элемента он базу не лезет, а лезет лишь в случае, когда блока данных этого элемента нет в памяти. Другими словами - надо написать кэш, пул. Не самая простая задача, но для однопоточного read-only кэша - не очень сложная. Однако - а если данные надо будет менять и записывать обратно? А как часто записывать? А как отслеживать "программа сломалась и упала не записав данные" ? А если будет несколько потоков (или несколько копий программы на разных компьютерах? Есть такое ругательство "когерентность кэша" https://habrahabr.ru/company/alconost/blog/344652/ То есть возвращаемся к "нужен программист", либо готовый, либо топикстартеру нужно быстро и довольно-таки глубоко изучать програмимрование "в целом" ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:43 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД Код: pascal 1. Память переполнилась, нужно выбросить какой-то блок из памяти. Как определить, какими блоками можно пожертвовать? Как сделать, чтобы программа не запуталась и не начала читать уже выброшенный из памяти блок там ,где он когда-то давно был? я знаю волшебные слова ARC и LRU, а топикстартер? это примерно как мне сейчас поручить с чистого листа рассчитать самый примитивный реактор, Ферми или Ф-1 там для человека в етме - делов на один вечер, а мне года не хватит ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:47 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДАндрей Игоревич Давай чуть-чуть поболтаем. Можно данные в базу/из базы записывать не по одному элементу, а блоками. К примеру, есть у тебя 4-х мерный массив, каждая размерность шириной в сто тыщ. Если работать с одной плоскостью (100 000 х 100 000), то понадобится всего 10 млн ячеек памяти. Нормально. Если по твоим алгоритмам ты долго работаешь именно в одной плоскости, то работай с памятью, а как перескочишь на другую - сбрасывай этот блок в базу, доставай оттуда новый и работай с ним. Можно сразу несколько блоков хранить в памяти (например, последние из используемые, или самые часто используемые, или как тебе подсказывает твоя логика обработки данных). Если честно, то именно так я хотел сделать, но при помощи типизированных файлов, а не БД. Есть ли какие-либо преимущества у БД для подобного вида операций? Тем более что у типизированного файла проще блоки реализовать. чччД Как это делать. Можно написать класс-"менеджер", который имитирует работу с многомерной табличкой. Ты ему указываешь координаты данных, а он тебе возвращает их И ради отдельного элемента он базу не лезет, а лезет лишь в случае, когда блока данных этого элемента нет в памяти. Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. Как с этим работать. Также, как с массивом. Только его (экземпляр "массива-класса") следует создать: Код: pascal 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. Скорость вырастет не в 3-10 раз, а побольше. Хз что такое класс-"Менеджер" (не, ну я узнал, что в Москве есть такое ООО), но суть я, наверно, понял. У данного способа есть недостаток. Если мне надо пройтись по всему массиву данных (весьма популярный "запрос"), как бы "вдоль" массива (вдоль - по времени) - то придётся поочерёдно загружать - выгружать всё БД для каждого запроса, либо дробить БД на более мелкие элементы. Хотя я ещё и не проверял (и возможно жестоко заблуждаюсь), но мне кажется, что запрос с диска и так устроит меня по времени отклика. Пока меня больше не устраивает время заполнения базы. Но завтра попробую много столбцов. Ну и как уже писал, мне больше вариант с типизированными файлами нравится для работы с "Блоками", тем более приложение на делфи 2ГБ типизированный файл с ССД загружает за несколько десятков секунд, сомневаюсь что БД так умеет. А вообще рабочий день закончился, надо бы отвлечься чтоль, а то от одного компа пересел за другой, что за жизнь то такая :). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:48 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичКилоКилоКило значений :), я думал это очевидно тут недавно ракету запускали. ракете было очевидно, как работает разгонный блок. разгонному блоку было очевидно, как работает ракета в результате все упало, потому что очевидности оказались разные также были байка про ракету Ариан-4, кажется программистам из НАСА было очевидно, что все физические единицы считаются в имперской системе французским программистам было очевидно, что все физические единицы считаются в СИ интеграторам было очевидно, что всем все очевидно, и они просто объединили эти части в одну программу, не проверяя напрасно и без того очевидного впрочем, возможно это просто байка ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch... Абстрактному программисту в вакууме фиг объяснишь, что нужно, тут не бухгалтерия, а чуток посложнее. А грамотный прикладник наверняка где-нибудь уже работает, фиг такого найдешь, т.к. такие недоступны - можно считать, что их нет. Тут нужен специалист в прикладной области, умеющий или желающий научиться чуть-чуть программировать. Человек это есть - ТС. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:54 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДчуть-чуть программировать оптимистично ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 19:57 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичУ данного способа есть недостаток. Если мне надо пройтись по всему массиву данных (весьма популярный "запрос"), как бы "вдоль" массива (вдоль - по времени) - то придётся поочерёдно загружать - выгружать всё БД для каждого запроса, либо дробить БД на более мелкие элементы. если будешь использовать типизированные файлы - то размер блока может быть любым. ... Можно данные массива хранить, "раскладывая" их по разным плоскостям. Данные будут храниться в избыточном (в разы) количестве, да, но зато ты сможешь пройтись "вдоль" массива также быстро, как и "поперек". ... Я на всякий случай предложил: мало ли, вдруг твои алгоритмы предполагают длительную работу в отдельных "срезах" массива, зная эту особенность, можно здОрово выиграть описанным выше способом. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичтем более приложение на делфи 2ГБ типизированный файл с ССД загружает за несколько десятков секунд я бы еще подумал на тему Memory Mapped Files они могут "загружаться в память" вообще мгновенно но у них тоже есть недостатки. https://ru.wikipedia.org/wiki/Отображение_файла_в_память ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:03 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, типизированный файл скорее всего будет глючить при размерах >2ГБ ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:03 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochчччДчуть-чуть программировать оптимистично Реалистично. Умение кодить само по себе ценности не представляет. Чуть-чуть умеющий кодить прикладник с большой вероятностью создаст адекватную прикладную систему. А кодер, слабо знающий прикладную область, не создаст такую систему никогда. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:07 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДЧуть-чуть умеющий кодить прикладник с большой вероятностью создаст адекватную прикладную систему. .....пока система маленькая и не упирается в возможности железа. А когда надо начинать наворачивать кэши с разными срезами - это уже когда все, тупой метод "в лоб" перестал работать. И дальше.... как повезет. Начинается увеличение сложности, это влечет за собой свои и чужие ошибки, которые нужно вовремя опознать, потом найти, потом исправить.... Но "первое блюдце" он найдёт и вылакает без вопросов, спорить глупо. "Пока котлеты не подгорали" у топикстартер было всё отлично. А потом данные доросли до 2ГБ и началось..... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:10 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochчччДЧуть-чуть умеющий кодить прикладник с большой вероятностью создаст адекватную прикладную систему. .....пока система маленькая и не упирается в возможности железа. А когда надо начинать наворачивать кэши с разными срезами - это уже когда все, тупой метод "в лоб" перестал работать. И дальше.... как повезет. Начинается увеличение сложности, это влечет за собой свои и чужие ошибки, которые нужно вовремя опознать, потом найти, потом исправить.... Но "первое блюдце" он найдёт и вылакает без вопросов, спорить глупо. "Пока котлеты не подгорали" у топикстартер было всё отлично. А потом данные доросли до 2ГБ и началось..... Ну ничего, будем потихоньку расти и развиваться :). Вообще моя работа больше связана с расчётом на уже созданных мощнейших программных комплексах. Я же просто подготавливаю и визуализирую по средствам своих программы исходные данные и результаты, хотя в будущем хочу и больше сам делать. А вообще по факту львиная доля серьёзных расчетных программ с точки зрения программирования весьма примитивны, там вся сложность в методике и математике, ну и исходных данных, конечно. чччДАндрей ИгоревичУ данного способа есть недостаток. Если мне надо пройтись по всему массиву данных (весьма популярный "запрос"), как бы "вдоль" массива (вдоль - по времени) - то придётся поочерёдно загружать - выгружать всё БД для каждого запроса, либо дробить БД на более мелкие элементы. если будешь использовать типизированные файлы - то размер блока может быть любым. ... Можно данные массива хранить, "раскладывая" их по разным плоскостям. Данные будут храниться в избыточном (в разы) количестве, да, но зато ты сможешь пройтись "вдоль" массива также быстро, как и "поперек". ... Я на всякий случай предложил: мало ли, вдруг твои алгоритмы предполагают длительную работу в отдельных "срезах" массива, зная эту особенность, можно здОрово выиграть описанным выше способом. Ну я так и хотел по сути сделать. Так что попробую. AriochчччД, типизированный файл скорее всего будет глючить при размерах >2ГБ Ну значит будет много файлов по 2Гб :). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 20:59 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochYuRockА "у себя" сделать "развернутый" запрос с этими параметрами - и получить запись. ??????Ну что ты как маленький. FOR SELECT и UPDATE на каждую запись с логированием всех полей, ты ж сам предлагал этот вариант. Но только для отладки, а на на постоянную основу. Это я не ради продолжения спора ответил. Для ясности просто. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 21:05 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch...пока система маленькая и не упирается в возможности железа. А когда надо ... Есть масса задач, которые имеют свойство просто решаться. Задача возникла - решилась - задачи нет. Весь цикл. Не требуется накапливать историю, не требуется обслуживать распухающую базу. Пример: запустил MSWord, написал письмо, вставил картинку - распечатал, отправил по почте, оригинал уничтожил. И каждый используемый программный компонент в сто тысяч раз сложнее самой сложной системы, которая крутится на базе милых сердцу СУБД, и он точно не упирается в железо. ... А когда "упрется в железо" - то и здесь "программист" ничем не поможет: он наверняка с таким не сталкивался, а если и сталкивался, то весь его опыт находится исключительно в области его конкретного случая. И к моменту, когда "упрется", ТС сам кого хочешь в блюдце тыкать будет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 21:17 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревич...Arioch...типизированный файл скорее всего будет глючить при размерах >2ГБ Ну значит будет много файлов по 2Гб :). Нормально там все. Нужно просто использовать не паскалевские средства доступа ("вещь в себе"), а (например) TFileStream. Читай/пиши любой элемент с точностью до байта. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.02.2018, 21:21 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичпоинтересуюсь у друга, который как раз работает с программами для АЭС как там всё реализовано на эту темукак раз на днях читал что то ли запустили то ли собираются спутник набитый практически обычными мирскими флэхами на посмотреть как же оно там будет жить Ariochвполне вероятно что этот запрос тоже буде тв твоём клиенте, так что все равно придется клиента обновлятьили вполне вероятно что в клиенте не будет так что клиента при смене запроса обновлять не придется ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 09:43 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, ээээ.... тут кто-нибудь спрашивал за версию Delphi или Лазаря ? Потому что в Delphi 5 и TFileStream точно так же 32-битный В Delphi XE2 он 64-битный. А где было переключение я не в курсе. Вот из такого рода грабель, которые надо на автомате замечать и проверять, и во многом состоит опыт прикладного программиста TFileStream всё таки очень абстрактная базовая вещь, над ней бы сделать типизированную обёртку на генериках например... Кстати, тот самый CachedBuffers вполне возможно оно и есть. Ну или хотя бы TBufferedFileStream Кроме того, всё таки когда речь о доступе то вдоль то поперек к мега-массиву - я бы подумал о переходе на 64-битный Delphi и MMF. Сделал вид, что весь файл целиком загружен в память - и гуляй по нему как захочется, а система пусть подгружает по мере необходимости ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 12:18 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
vavan, микроспутник на "полетать пару недель, упасть и сгореть" вполне проживёт свой срок ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 12:18 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей ИгоревичЕсть ли какие-либо преимущества у БД для подобного вида операций? В принципе есть, но у ДРУГИХ баз данных, их даже часто называют не базами, а хранилищами. Firebird - чётко выраженный сервер для OLTP - https://ru.wikipedia.org/wiki/OLTP Если же вы хотите визуализировать большие объёмы редко изменяемых данных, то ваша область - OLAP. https://ru.wikipedia.org/wiki/OLAP Ну и дальше по гуглю для этой аббревиатуры https://ru.wikipedia.org/wiki/OLAP-куб http://www.olap.ru/basic/alpero2i.asp https://habrahabr.ru/post/126810/ и т.д. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 12:25 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
AriochчччД, ээээ.... тут кто-нибудь спрашивал за версию Delphi или Лазаря ? Потому что в Delphi 5 и TFileStream точно так же 32-битный В Delphi XE2 он 64-битный. А где было переключение я не в курсе. Вот из такого рода грабель, которые надо на автомате замечать и проверять, и во многом состоит опыт прикладного программиста TFileStream всё таки очень абстрактная базовая вещь, над ней бы сделать типизированную обёртку на генериках например... Кстати, тот самый CachedBuffers вполне возможно оно и есть. Ну или хотя бы TBufferedFileStream Кроме того, всё таки когда речь о доступе то вдоль то поперек к мега-массиву - я бы подумал о переходе на 64-битный Delphi и MMF. Сделал вид, что весь файл целиком загружен в память - и гуляй по нему как захочется, а система пусть подгружает по мере необходимости Что ты все нагнетаешь на пустом месте. Прикладной программист - это тот, кто знает прикладную область, кто ее знает луче, чем ТС? А кодить и обезьяна сможет. Про версию Delphi он сам говорил, сперва он использовал D7, после - XE 10.1. Не знаю, что там в 10.1, но в D7 у TStream свойства Size и Position имеют тип Int64, метод CopyFrom принимает и возвращает In64, метод Seek перегружен, имеет два интерфейса -и с Integer , и с Int64 - в итоге фактически используется последний вариант, что еще надо для работы с большими файлами? ... И совершенно непонятны твои усилия впарить новичку глючные поделия блаженного оптимизатора. Разве что действительно хочешь убедить ТС в мысли, что без "профи" он не сможет справится. Непонятно только, для чего это тебе нужно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 13:11 |
|
||
|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччДАндрей Игоревич... И стоп в 2 раз. А сколько можно столбцов в БД сделать? 350 можно? Никаких подводных камней не будет? Это, как мне кажется, очень так ускорит заполнение. Много можно. Видел табличку в 500 полей. Главное, чтобы данных там не более 64кБайт (реально - чуть поменьше) на одну запись набралось. В общем стало ещё медленней, но, возможно, из-за того, что отказался от строки в пользу Float (может операция преобразования строки в число в самой БД требует время). Ладно, пока от БД отойду, попробую через TFileStream. AriochАндрей ИгоревичЕсть ли какие-либо преимущества у БД для подобного вида операций? В принципе есть, но у ДРУГИХ баз данных, их даже часто называют не базами, а хранилищами. Firebird - чётко выраженный сервер для OLTP - https://ru.wikipedia.org/wiki/OLTP Если же вы хотите визуализировать большие объёмы редко изменяемых данных, то ваша область - OLAP. https://ru.wikipedia.org/wiki/OLAP Ну и дальше по гуглю для этой аббревиатуры https://ru.wikipedia.org/wiki/OLAP-куб http://www.olap.ru/basic/alpero2i.asp https://habrahabr.ru/post/126810/ и т.д. Ну некоторый ликбез произвел, но создалось впечатление, что для меня это избыточна, может позже поподробнее изучу. AriochКроме того, всё таки когда речь о доступе то вдоль то поперек к мега-массиву - я бы подумал о переходе на 64-битный Delphi и MMF. Сделал вид, что весь файл целиком загружен в память - и гуляй по нему как захочется, а система пусть подгружает по мере необходимости Ну я и так 64- битный теперь использую (там где не использую БД), а вариант с файлом на жестком диске подключаемом "как из оперативы" (забыл как это называется) мне ещё в начале этой темы предлагали, у меня не получилось :), и я пошел другими путями. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 13:15 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Андрей Игоревичвариант с файлом на жестком диске подключаемом "как из оперативы" (забыл как это называется) мне ещё в начале этой темы предлагали, у меня не получилось Это называется MMF :-) 21174521 чччД, TStream не предназначен дял работы с типизированными файлами. Ни TFileStream, ни TBufferedFileStream такой работы не предоставляют. В результате ТСу придется в каждом вызове заниматься копипастом, переходя между логикой доступа к записям к логике доступа к байтам и обратно. А где массовый копипаст - там и описки, которые довольно трудно заметить. Особенно когда надо будет работать с разными файлами, в которых разные структуры и размеры записей, перепутать в запарке волшебную константу раз плюнуть. Либо ТСу придётся делать свою обёртку для типизированного доступа поверх TStream. И как минимум по началу она тоже будет "глючной поделкой". А оптимизатор, хотя и фонтанирует блаженством, практики кодинга имеет поболее ТСа. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 13:40 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch... чччД, TStream не предназначен дял работы с типизированными файлами. Ни TFileStream, ни TBufferedFileStream такой работы не предоставляют. В результате ТСу придется в каждом вызове заниматься копипастом... ... И как минимум по началу она тоже будет "глючной поделкой". ... А оптимизатор, хотя и фонтанирует блаженством, практики кодинга имеет поболее ТСа. ... Непонятно, что ты хочешь доказать. PS: кстати, пузыри пошли. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 13:53 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
чччД, Что у других библиотек, типа CachedBuffers, вполне могут быть практические преимущества перед TStream TStream это типа как модно-современно, да ещё и искаропки, но слишком абстрактно и типизированные файлы заменяет плохо. А потому пока ТС в активном поиске, ему лучше сразу проверить несколько вариантов организации чтения/записи файлов, чем завязаться на сырой (raw) TStream и потом иметь маленькие, но постоянные проблемы с копипастом Ergo чччДтвои усилия впарить здесь совсем не каждую фигню от SOFT-FOR-что-то-там, а впарить поиск (или самостоятельное написание, раз уж программист - это не профессия) более подходящих для его данных библиотек, чем "TStream патамушто TStream" ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 15:01 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch...TStream это типа как модно-современно... "Вопросов больше не имею" - (с). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 15:38 |
|
||

|
Как работать с очень большими масивами
|
|||
|---|---|---|---|
|
#18+
Arioch.. много слов про якобыминусы БДтут вообще-то начали с того, что все данные в массивах у ТС просто не помещаются в памяти. и вместо того, чтобы городить свою мини-субд (а этим обязательно все кончится, так как аппетит приходит во время еды), ему (совершенно правильно), посоветовали взять уже готовое. что будет легко, - нет, не обещали. но делать свое - будет еще труднее. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.02.2018, 16:12 |
|
||

315 сообщений из 315, показаны все 13 страниц
|
|
Форумы
[новые:0]
/ Delphi
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Как работать с очень большими масивами
[новые:0]
