Гость

Форумы
[новые:0]
/ C++
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
vector на триллион объектов
[новые:0]
25 сообщений из 332, страница 3 из 14
|
|
|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Можем даже заниматься системной оптимизацией полнотекстового. Надо просто поставить задачу. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 11:46 |
|
||






|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
petravЧто хранится в бинарном дереве? То же что и обычно - ключ, полученный какими-то преобразованиями данных. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 11:47 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton Можем даже заниматься системной оптимизацией полнотекстового. Надо просто поставить задачу. Мы много чем можем можем заняться))). Просто ТС не может поставить задачу. )) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 11:47 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Dimitry Sibiryakov petravЧто хранится в бинарном дереве? То же что и обычно - ключ, полученный какими-то преобразованиями данных. Там хранится ключ и указатель на физическое местоположение строки (RowId) в datafile. Это для листовых узлов индекса. Для не-листовых - там линки на соседние блоки индекса. Его формат немного отличается от указателя. Например Oracle хранит группу целых чисел (номер файла, номер блока в файле (это тот самый 8к блок файловой системы), и номер строки внутри блока). И дополнительно objectId. Это кажется надо для поддержки кластеризованных таблиц. Например. Фрагмент блока индекса. (Я пишу в формате JSON чтоб было понятно. На самом деле там - RAW.) keyrow_id (in JSON)mayton{ file=1, block=25, row=3, objId=... }Petro{ file=1, block=25, row=4, objId=... }........ В таблице есть блок номер 25 где лежат 2 строки проиндексированные по ключам mayton, Petro. Понятно что file=1 это уже не файл где лежит индекс а файл где лежит индексируемая таблица. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:00 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton, Замечательно. Осталось выяснить уникальность ключа и работает ли по нему поиск) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:03 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton Dimitry Sibiryakov пропущено... То же что и обычно - ключ, полученный какими-то преобразованиями данных. Там хранится ключ и указатель на физическое местоположение строки (RowId) в datafile. Это для листовых узлов индекса. Для не-листовых - там линки на соседние блоки индекса. Я не это имел в виду. Уточню: в случае индекса по строковому полю, что представляет собой ключ? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:07 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Тоже работает. С точки зрения Oracle (например) - все индексы являются Unique по своей структуре данных. Неуникальные там достигаются изменением алгоритма в плане оптимизатора. Как точно - я щас не помню надо почитать. Дядка Том писал об этом. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:11 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
petrav mayton пропущено... Там хранится ключ и указатель на физическое местоположение строки (RowId) в datafile. Это для листовых узлов индекса. Для не-листовых - там линки на соседние блоки индекса. Я не это имел в виду. Уточню: в случае индекса по строковому полю, что представляет собой ключ? Абсолютную копию этой-же строки. Тоесть строка "mayton" будет физически скопирована с таблицы в индекс. Но если тебя интересует экономия места - то можно строить Index-Organized-Tables (это гибрид таблицы и индекса). Но там есть ограничения. Нельзя дополнительные поля проиндексировать. Только primary. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:13 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton Да милисекунды это долго. Дольше чем просто память. Но обычно все DBMS прогревают в кешах корневые вершины индексов и если с индексом долго работать то в учет времени можно брать уже листовые узлы. Как же происходит балансировка такого дерева, если в кешах только верхняя часть дерева? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:36 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
maytonАбсолютную копию этой-же строки. В простейшем случае - да, но обычно применяют преобразования для получения CI AI. И префиксную компрессию. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:44 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
petrav mayton Да милисекунды это долго. Дольше чем просто память. Но обычно все DBMS прогревают в кешах корневые вершины индексов и если с индексом долго работать то в учет времени можно брать уже листовые узлы. Как же происходит балансировка такого дерева, если в кешах только верхняя часть дерева? В онлайне. Оно растет от листьев к корню. Грубо говоря - малый индекс - это 1 блок. Когда инфа больше чем 8 килобайт - происходит split блока на 2 части вверх поднимается новый ключ-медиана который делит условно все пространство ключей на 2 диапазона. Те что больше ключа ложаться в правое поддерево. А те что меньше в левое. Корневой узел хранит 1 ключ и два указателя влево и справо. А а дочерние узлы - листовые хранят уже ключи и ROW_ID. А вот примерно так будет выглядеть индекс с 3 уровнями. Это когда после сплитов наш корневой узел опух до предела и произошел новый сплит с поднятием нового корня еще выше вверх. 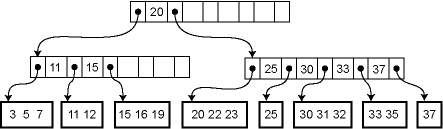 Работает тоже самое алгоритм бинарного дерева просто заточенный под работу дисковыми блочками чтоб не создавать лишней нагрузки. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:50 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Работа кешей БД - это прозрачный механизм для движка. Ему по большему счету все равно откуда читать. Просто исходим из предположения что наиболее горячие блоки сконцентрированы вверху дерева. Есть там еще такой интересный параметр как фактор кластеризации. Он .. грубо говоря показывает насколько сильно мы будем промахиваться мимо кеша (таблицы) если будет скан индекса с первого ключа по последний. Это актуально для запросов в RANGE-предикатом. Типа where date between d1 and d2. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:53 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton Тоже работает. С точки зрения Oracle (например) - все индексы являются Unique по своей структуре данных. Неуникальные там достигаются изменением алгоритма в плане оптимизатора. Как точно - я щас не помню надо почитать. Дядка Том писал об этом. Тут задают вопрос об уникальности с точки зрения бизнеса. Чтобы full scan не было. То есть перебора всех строк подряд. Мы глубоко в физику процесса полезли. Что будет индексом к "Война и мир"? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 12:58 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton, Без блока where вся твоя физика процесса индексации не имеет смысла. Так как ключи могут быть не использованы вообще оптимизатором. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:00 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Есть отдельный API который бегает мимо кешей. DIRECT. Типа прямой. Он нужен для массовых операций типа count(*). И чтобы count своей селективностью не засирал кеш - его кидают отдельной операцией которая не влияет на состояние кеша. Тоже самое к массовым процессам типа ETL. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:01 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
PetroNotC Sharp mayton Тоже работает. С точки зрения Oracle (например) - все индексы являются Unique по своей структуре данных. Неуникальные там достигаются изменением алгоритма в плане оптимизатора. Как точно - я щас не помню надо почитать. Дядка Том писал об этом. Тут задают вопрос об уникальности с точки зрения бизнеса. Чтобы full scan не было. То есть перебора всех строк подряд. Мы глубоко в физику процесса полезли. Что будет индексом к "Война и мир"? Я ведь тоже не могу ответить на этот вопрос при такой обобщённой постановке. Прямой ответ - смотрите в excecution plan и добивайтесь того чтобы FTS операция была заменена на index-scan, index-range, e.t.c. Есть еще варианты - использовать partition iterator но это все требует деталей которых у меня нет. Оптимизаторы часто используют логику наподобие нейро-сети. Тоесть принимают решение исходя из десятка настроечных параметров и не один DBA не может наперед сказать что план будет хорош или плох. Оптимизация плана - это итеративный процесс. Смотришь. Изменяешь. Смотришь. Изменяешь... итд. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:05 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton, Просто не люблю усложнять когда нет вообще постановки. Пример: - ТС не говоил что будут запросы. Поэтому индексом PK к колонке строк Война и мир будет автоинкремент. Чтобы при родах вектора структуру книги не потерять. Всё. Автор больше не усложнял никакими доп требованиями. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:20 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton, >Прямой ответ - смотрите в excecution plan До плана далеко. Мы не построили Модель. Не знаем типы данных в колонках и какой индекс строить руками при проектировании таблицы. Индексов то полно всяких). Я выше предложил МИНИМАЛЬНЫЙ. Автоинкремент PK Пусть автор докажет что это не работает. "ТС работает больше отвечающих" (с) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:27 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
По поводу войны и мира. Что ты хочешь найти? Страницу документа? Номер строки? Или Строка и номер слова в строке? Хочешь ли ты строгий поиск по совпадению? Или ты хочешь поиск по основе слова? Или ты хочешь стемминг и лематизацию и способность кода находить синонимы и похожие слова и опечатки. Это все дополнения которые на 100 и более % меняют постановку и заставляют нас прыгать от обычного индекса - к индексу Би-грамм и к фильтру Блума. И к фасетизации всех данных. Текстовый поиск это вообще офигенски сложная дисциплина. И я в ней плаваю. Я знаю ее где-то на 10% и там много подводных камней. Всё что я описывал выше это обычный классический поиск в БД который к тексту вообще-то отношения не имеет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:37 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton, Конечно. Поэтому кеши, деревья, и еще раз кеши мимо темы топика. Имхо. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 13:42 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
Хорошо. Тогда я умолкаю. Подожду Алексея с его тера-массивом структур. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 14:06 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
mayton petrav пропущено... Как же происходит балансировка такого дерева, если в кешах только верхняя часть дерева? В онлайне. Оно растет от листьев к корню. Грубо говоря - малый индекс - это 1 блок. Это я понимаю, оффкос, примерно. Простой вопрос. У нас террабайт строк, мы ещё создали индекс на террабайт. При этом 99% этого индекса лежит на диске. Добавление одной строки не приведёт ли к полной перестройке дерева? Т.е. к полному поднятию терребайтного индекса с диска и обратной записи на диск этого террабайта. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 14:10 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
petravДобавление одной строки не приведёт ли к полной перестройке дерева? Нет, максимум три блока при сплите. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 14:12 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
petrav mayton пропущено... В онлайне. Оно растет от листьев к корню. Грубо говоря - малый индекс - это 1 блок. Это я понимаю, оффкос, примерно. Простой вопрос. У нас террабайт строк, мы ещё создали индекс на террабайт. При этом 99% этого индекса лежит на диске. Добавление одной строки не приведёт ли к полной перестройке дерева? Т.е. к полному поднятию терребайтного индекса с диска и обратной записи на диск этого террабайта. Нет конешно. Еслиб такой ужас был тогда и загрузка данных в таблицу лагала-бы. В наихудшем случае может быть split. Но это вместо 4 IOPS, будет чуть больше. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 14:14 |
|
||

|
vector на триллион объектов
|
|||
|---|---|---|---|
|
#18+
ну вы писАть блин... PetroNotC Sharp Алексей Роза есть какие-то ограничения в практическом применении векторов? если вектор вырастет до триллиона структур и будет постоянно висеть в памяти, есть ли какие-то риски? То есть памяти хватает и ты в курсе как это решать? Тогда никаких рисков. Работай. Памяти хватает. Не хватает опыта. Что будет через 5 лет нахождения информации в памяти? Каков шанс потерять рандомный байт? mayton Но для начала. Давай просто сделаем такой confirm, что алгоритмы поиска на диске в принципе ничем особо не отличаются по complexity от алгоритмов по оперативке. Формула - таже самая. С логарифмом в основе. Тоже самое B+Tree дерево - это сжатое в блоки бинарное дерево поиска. Да это основы. Ясно, что и там, и там стандартная хексовая таблица. Было бы странно, если бы память и HDD хранили инфу по-разному, ведь и то, и то - память. mayton Да милисекунды это долго. Дольше чем просто память. Но обычно все DBMS прогревают в кешах корневые вершины индексов и если с индексом долго работать то в учет времени можно брать уже листовые узлы. не надо DBMS. mayton сумеем придумать access path такой короткой длины чтобы оперативная память и диск работали в тандеме и находили данные так быстро как только возможно не надо. mayton Есть также альтернативные разработки (dbms Tarantool) которые улучшают даже B+Tree индекс. аааААааааАааАААаААаАааа mayton Хорошо. Тогда я умолкаю. Подожду Алексея с его тера-массивом структур. ну строго говоря, самое близкое к моей задаче - это индекс. но это не задача... у меня нет вопросов про то, как индексировать есть только вопрос заданный выше... и ещё один теперь можно обсудить - про полнотекстовый поиск, раз уж его затронули. Я так понимаю, чтобы в "Войне и мир" найти слово "кровь" надо всю войну разложить в столбики по одинаковым словам? Вообще у гугла есть описание, как устроен поиск... там 3.14здецки сложно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.06.2020, 14:47 |
|
||

25 сообщений из 332, страница 3 из 14
|
|
Форумы
[новые:0]
/ C++
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
vector на триллион объектов
[новые:0]
