Гость

Форумы
[новые:0]
/ Microsoft SQL Server
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
ускорить удаление с отбором по времяшке
[новые:0]
22 сообщений из 22, страница 1 из 1
|
|
|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Всем добрый день! Есть служебная таблица, которую нужно периодически чистить. Таблица «горячая», много добавлений-изменений от бизнес-логики, поэтому хочется, чтобы сборщик мусора максимально не отсвечивал. Получилась конструкция из скрипта ниже: сначала создаем временную таблицу со списком id на удаление, потом удаляем в цикле с отбором по этой времяшке – так получается стабильное время транзакций и минимальное число логических чтений. В целом, меня тут все устраивает. Единственное, за что цепляется глаз: сортировка перед Merge Join. (полный план - во вложении) 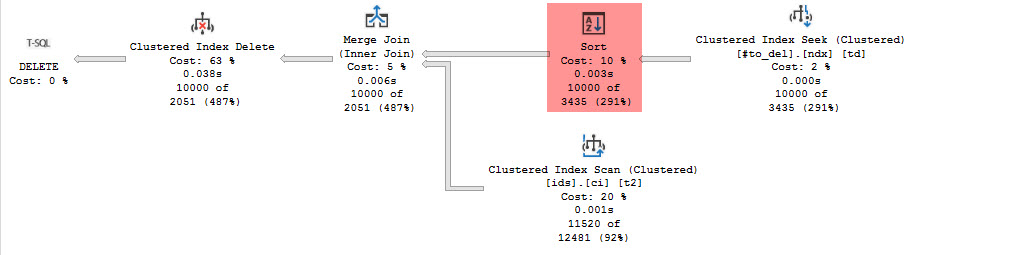 Понятно, почему так получается: сиквел не знает, что num и id растут «в одну сторону», он ожидает примерно такой ситуации: NUM ID10 515 2 ну и перестраховывается дополнительной сортировкой. Собственно, вопрос: может быть я что-то пропустил и от этой сортировки можно избавиться? Как-то все-таки подсказать движку, что значения постоянно равномерно растут и выбрав растущие num, он выберет так же растущие id? Сразу добавлю: индекс по num, id или id, num не помогает Код: Хотел приложить csv с примером таблицы ids, но даже архив оказался слишком большим. Поэтому выложил его снаружи: https://drive.google.com/file/d/1-ddrz3fKwvw70jBeUzan-tB91GWvAnT9/view?usp=sharing Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 12:01 |
|
||





|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl Собственно, вопрос: может быть я что-то пропустил и от этой сортировки можно избавиться? Как-то все-таки подсказать движку, что значения постоянно равномерно растут и выбрав растущие num, он выберет так же растущие id? Сразу добавлю: индекс по num, id или id, num не помога сделайте на # таблице кластерый индекс по полю сортировки, тогда на # будет ordered scan, выдающий уже правильно отсортированный датасет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 12:07 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl, У вас поле obj никак не проиндексировано, а в запросе на удаление оно используется в джойне. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 12:10 |
|
||


|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl много добавлений-изменений от бизнес-логики Если их действительно много, то без партиционирования с чисткой будет задница, какие бы ты индексы не поприкручивал - сами уже это проходили. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 12:17 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl, У вас на сортировку тратится мизер, по сравнению со всем остальным. Потенциально гораздо хуже clustered index scan по "горячей" таблице в цикле. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 12:50 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 13:05 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
aleks222, @@rowcount ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 13:10 |
|
||


|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
aleks222, нет, к сожалению, получается хуже: куча перечитываний ids на каждой итерации для того, чтобы сформировать очередную #to_del И после этого - практически тот же план, что я привел в начале. 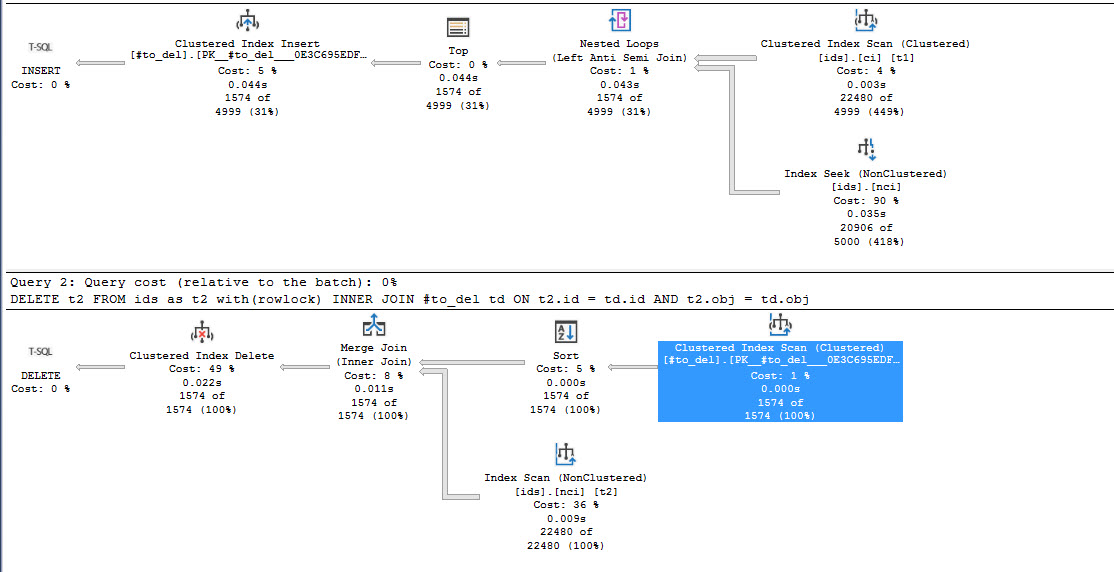 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 13:17 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Спасибо всем, перепробовал еще несколько вариантов. Можно сделать индекс во временной таблице по obj, id, num – доп. сортировка, естественно, пропадает. Но тогда для получения очередной пачки на удаление нужно делать сканирование всей временной таблицы. И это то, от чего я изначально бежал: на большой временной таблице у меня может быть много итераций. И чем ближе к концу цикла, тем дальше в таблице будут нужные значения num – то есть, удаление со временем будет деградировать. С тем же успехом можно просто сделать DELETE TOP (N) в цикле и не городить весь этот огород. Можно сделать кластерный индекс по obj, id и некластерный по num. Тогда сиквел отбирает записи по индексу с num и тут понимает, что ключи кластерного индекса у него же уже считаны – и опять уходит в сортировку (не говорю, что это хуже, чем key lookup, но это и не лучше исходного варианта) Ну и изначальный вариант, по сути мало отличающийся от предыдущего. В волшебном мире розовых пони я бы вообще выкинул поле num и фильтровал пачки по id (ну и сделал бы соответствующий индекс на таблице ids). Но в реальности id распределён неравномерно, в распределении возможны дыры, так что надёжнее все-таки принудительно пронумеровать времяшку. В целом, сортировка на стабильно коротком объёме видится меньшим злом, чем замедляющееся на каждой итерации сканирование таблиц. Всем еще раз спасибо, думаю, можно закрывать. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 13:18 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Лучший результат должен получиться при следующем подходе. 1. Выбираем в отдельную # таблицу очередные 1000 записей из общей # таблицы 2. Находим среди этих данных max_obj и min_obj 3. В запросе на удаление - используем # таблицу с 1000 записями, - добавляем условия с диапазоном min_obj - max_obj (obj >= @min_obj and obj <= @max_obj) на основную таблицу - для надежности, добавляем option(merge join) по идее, должен получиться план - со сканом # таблицы из 1000 записей - в зависимости от ключа кластерного индекса # таблицы из 1000 записей, возможно сортировка - range seek под основной таблице - merge join этих dataset-ов ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 13:33 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
а если использовать DELETE TOP(100...) ? должны удаляться "первые попавшиеся" строки. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 15:25 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Oleg_SQL а если использовать DELETE TOP(100...) ? должны удаляться "первые попавшиеся" строки. Да, но тредстартер не ищет легких путей.... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 15:29 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
msLex Лучший результат должен получиться при следующем подходе. 1. Выбираем в отдельную # таблицу очередные 1000 записей из общей # таблицы 2. Находим среди этих данных max_obj и min_obj 3. В запросе на удаление - используем # таблицу с 1000 записями, - добавляем условия с диапазоном min_obj - max_obj (obj >= @min_obj and obj <= @max_obj) на основную таблицу - для надежности, добавляем option(merge join) по идее, должен получиться план - со сканом # таблицы из 1000 записей - в зависимости от ключа кластерного индекса # таблицы из 1000 записей, возможно сортировка - range seek под основной таблице - merge join этих dataset-ов Судя по страданиям тредстартера у него больше записей, которые нужно удалить, чем записей, которых удалять не нужно. 1. Выбираем ВСЕ, что НЕ нужно удалять. 2. Тупо удаляем все, что не входит в набор 1. 3. Пачками не более 5000 шт. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 15:34 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
aleks222 Oleg_SQL а если использовать DELETE TOP(100...) ? должны удаляться "первые попавшиеся" строки. Да, но тредстартер не ищет легких путей.... Зачем делать просто, когда можно делать сложно? Тем более, что простые пути ведут к неожиданным последствиям: https://dba.stackexchange.com/questions/246833/deleting-millions-of-records-on-sql-server-14-0 aleks2221. Выбираем ВСЕ, что НЕ нужно удалять. 2. Тупо удаляем все, что не входит в набор 1. 3. Пачками не более 5000 шт. Ну то есть у нас на каждой итерации удаления будет какой-нибудь Nested Loops для проверки на вхождение в "белый список" (из шага 1). А если этот список окажется большим? Как-то рискованно, я уж лучше с моим Merge join останусь Сразу в сторону: пока проблемы с очисткой мусора выстреливают хоть и метко, но редко. Так что про партиционирование пока думать рано, но когда (и если) этот скрипт перестанет справляться, разбитие на секции будет следующим шагом. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 16:23 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl Ну то есть у нас на каждой итерации удаления будет какой-нибудь Nested Loops для проверки на вхождение в "белый список" (из шага 1). А если этот список окажется большим? У вас, несомненно будет. Прочие используют индексы. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 16:33 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
aleks222 0wl Ну то есть у нас на каждой итерации удаления будет какой-нибудь Nested Loops для проверки на вхождение в "белый список" (из шага 1). А если этот список окажется большим? У вас, несомненно будет. Прочие используют индексы. Индекс не избавляет от Nested Loops, а чаще его требует. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 16:35 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
msLex Лучший результат должен получиться при следующем подходе. 1. Выбираем в отдельную # таблицу очередные 1000 записей из общей # таблицы 2. Находим среди этих данных max_obj и min_obj 3. В запросе на удаление - используем # таблицу с 1000 записями, - добавляем условия с диапазоном min_obj - max_obj (obj >= @min_obj and obj <= @max_obj) на основную таблицу - для надежности, добавляем option(merge join) по идее, должен получиться план - со сканом # таблицы из 1000 записей - в зависимости от ключа кластерного индекса # таблицы из 1000 записей, возможно сортировка - range seek под основной таблице - merge join этих dataset-ов Подумал над вашим вариантом и понял, что исходный план примерно так и работает: 1. из #to_del выбирается очередная пачка с отбором по num (номер по порядку) 2. выполняется та самая сортировка, из-за которой я написал пост. Находится минимальное и максимальное значение ключей 3. Дальше merge по найденным границам. 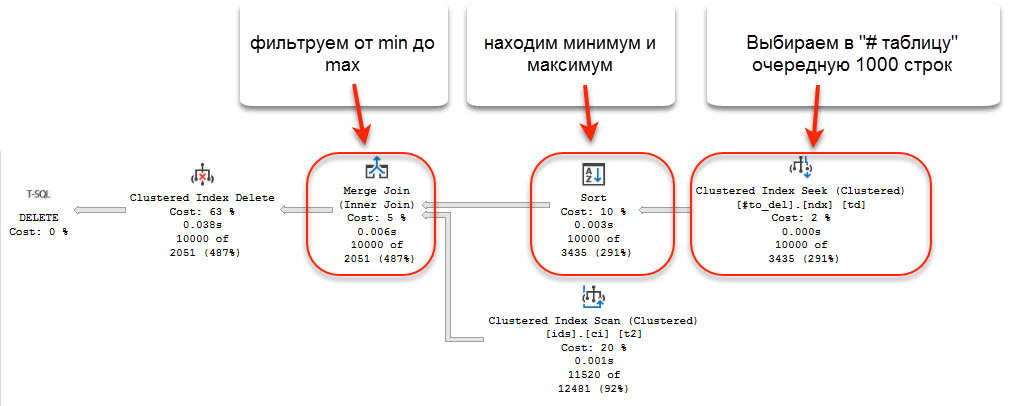 -- Как ни странно, последний вариант aleks222 оказался немножко лучше всех предыдущих попыток. Если сделать "белый список" и создать по нему индекс по obj, id - в плане выбирается Merge join. По суммарному числу чтений получается то же самое, что и мой исходный вариант, но нет сортировки, а число чтений из "белого списка" постепенно увеличивается от итерации к итерации - то есть, этот вариант действительно выгоден, когда в таблице удаляется на порядки больше строк, чем остается.  ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 19:09 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl, Вы не хотите понять простую вещь - ожидания при сканировании кластерного индекса нагруженной изменениями таблицы съедят весь ваш "выигрыш" от исключения сортировки. msLex предложил вариант ухода от такого сканирования. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 20:53 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
fkthat 0wl много добавлений-изменений от бизнес-логики Если их действительно много, то без партиционирования с чисткой будет задница, какие бы ты индексы не поприкручивал - сами уже это проходили. Аналогично, есть у нас база, в которой в две таблицы пишется в среднем 30 миллионов записей в день в каждую. Во второй таблице присутствует поле xml. Данные храним 60 дней. Каждый partition в отдельной файловой группе. Весит это чудо больше 20 ТБ. Без partitions процесс удаления работал 24/7 и все равно не успевал удалить все. С partitions - процесс удаления занимает 1 секунду, делаем switch partition в STAGE таблицу с той же структурой что и основная таблица, потом truncate STAGE таблицы. Ну а дальше alter partition scheme next used для повторного использования освободившейся файловой группы, alter partition function split range для добавления нового partition и alter partition function merge range для удаления старого. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 01.12.2020, 23:48 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
0wl msLex Лучший результат должен получиться при следующем подходе. 1. Выбираем в отдельную # таблицу очередные 1000 записей из общей # таблицы 2. Находим среди этих данных max_obj и min_obj 3. В запросе на удаление - используем # таблицу с 1000 записями, - добавляем условия с диапазоном min_obj - max_obj (obj >= @min_obj and obj <= @max_obj) на основную таблицу - для надежности, добавляем option(merge join) по идее, должен получиться план - со сканом # таблицы из 1000 записей - в зависимости от ключа кластерного индекса # таблицы из 1000 записей, возможно сортировка - range seek под основной таблице - merge join этих dataset-ов Подумал над вашим вариантом и понял, что исходный план примерно так и работает: 1. из #to_del выбирается очередная пачка с отбором по num (номер по порядку) 2. выполняется та самая сортировка, из-за которой я написал пост. Находится минимальное и максимальное значение ключей 3. Дальше merge по найденным границам. -- Как ни странно, последний вариант aleks222 оказался немножко лучше всех предыдущих попыток. Если сделать "белый список" и создать по нему индекс по obj, id - в плане выбирается Merge join. По суммарному числу чтений получается то же самое, что и мой исходный вариант, но нет сортировки, а число чтений из "белого списка" постепенно увеличивается от итерации к итерации - то есть, этот вариант действительно выгоден, когда в таблице удаляется на порядки больше строк, чем остается. фильтр по min max должен быть не в merge а в clustered index scan (который превратится в clustered index seek). Подсчет min max прям в запросе не поможет, т.к. при merge join оба набора данных читаются параллельно, и к моменту получения этих min max из # таблицы, применить их в качестве seek предиката уже не возможно. Именно поэтому требуется предварительный расчет этих значений (с вычеткой в отдельную # таблицу или без). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.12.2020, 11:36 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
msLex, invm, Да, спасибо. Я сначала думал, что merge передаст границы в нижнюю таблицу, поэтому и не заподозрил разницы. Проверил вживую - действительно, у обращения к ids появляются предикаты, он превращается в Seek и читает гораздо меньше строк. Ну и к слову, на какой-то итерации merge все-таки превращается в hash match - но это уже детали. Посмотрю подробнее, если будет мешать - можно действительно хинт добавить. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.12.2020, 12:14 |
|
||

|
ускорить удаление с отбором по времяшке
|
|||
|---|---|---|---|
|
#18+
Судя по косвенным признакам, у тредстартера всеж есть кластерный индекс (obj, id) в основной таблице Тредстартеру показано такое лечение: Код: sql 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. и будет ему щастье. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 02.12.2020, 12:54 |
|
||

22 сообщений из 22, страница 1 из 1
|
|
Форумы
[новые:0]
/ Microsoft SQL Server
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
ускорить удаление с отбором по времяшке
[новые:0]
