Гость

Форумы
[новые:0]
/ Программирование
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
[новые:0]
25 сообщений из 76, страница 2 из 4
|
|
|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Апдейт, знающие люди подсказали что с температурой не получится, надо как-то по другому. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 17:24:38 |
|
||





|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
private, это какая-то фейерия мыслей. Ты знаешь что нейросеть это - конструктор Lego. Как ты ее соберешь - она всегда рабоать будет. Как детишки балуются с современными играми-трансформерами. Что не соберут - бабушка и мама хвалят. Вот как дать смысл этой конструкции. Как выбрать ей подходящие входные данные. И как наполнить смыслом ее выход - вот это настоящий экспертный вопрос. P.S. Про температуру не слышал. Возможно имеется в виду скорость обучения? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 17:28:05 |
|
||


|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
авторЛинейная = sum(ki*хi**1) 1-й порядок (ну м.б. термин другой, шаг, стадия ...) = зависимость только от предыдущего значения. одномерная = F(x1) или F(x2) или ... Вроде так. Посмотрел регрессии - то что ты написал судя по всему называется непараметрическая регрессия, да тоже вариант, не знал про нее, спасибо. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 18:11:21 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
P.S. Про температуру не слышал. Возможно имеется в виду скорость обучения? Нет, это какой-то параметр функции активации нейросети, он как-то случайно чуть меняет ее форму и из-за этого немного меняется результат. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 18:41:06 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Мэйтон, его температура - в смысле добавить хаоса к поведению. Видимо у него мысль, чтобы не оказаться в 1-й попавшейся локальной яме. privateПо идее на такой "нагретой" сети можно затем сделать 1000 немного отличающихся прогнозов и построить по ним гистограмму. Вопрос - это будет что-то реально похожее на распределение А как ты понимамешь "распределением"? Да, какое-то ср.арифметическое у них будет - зуб даю. Будет также и какая-то дисперсия и даже вариации высших порядков. Зависит от того в какие ямы попадёт сетка, нам отсюда не видно. Вообще же, я впервые на форуме даю совет что-то изучить. В данном случае "плотность распределения", "функцию распределения", их св-ва, и остальной тервер впридачу ихотя бы часть матстатистики. (Например, что сумма независимых событий не должна превосходить 1 ......) П.С. Что, хоть, за универ, где такого качества знания дают за несколько лет изучения математики? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 19:02:56 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
exp98, я понял. Тогда к классической двухслойной сети. Можно добавить что температура это разброс начальных значений матриц W1, W2 на картинке. 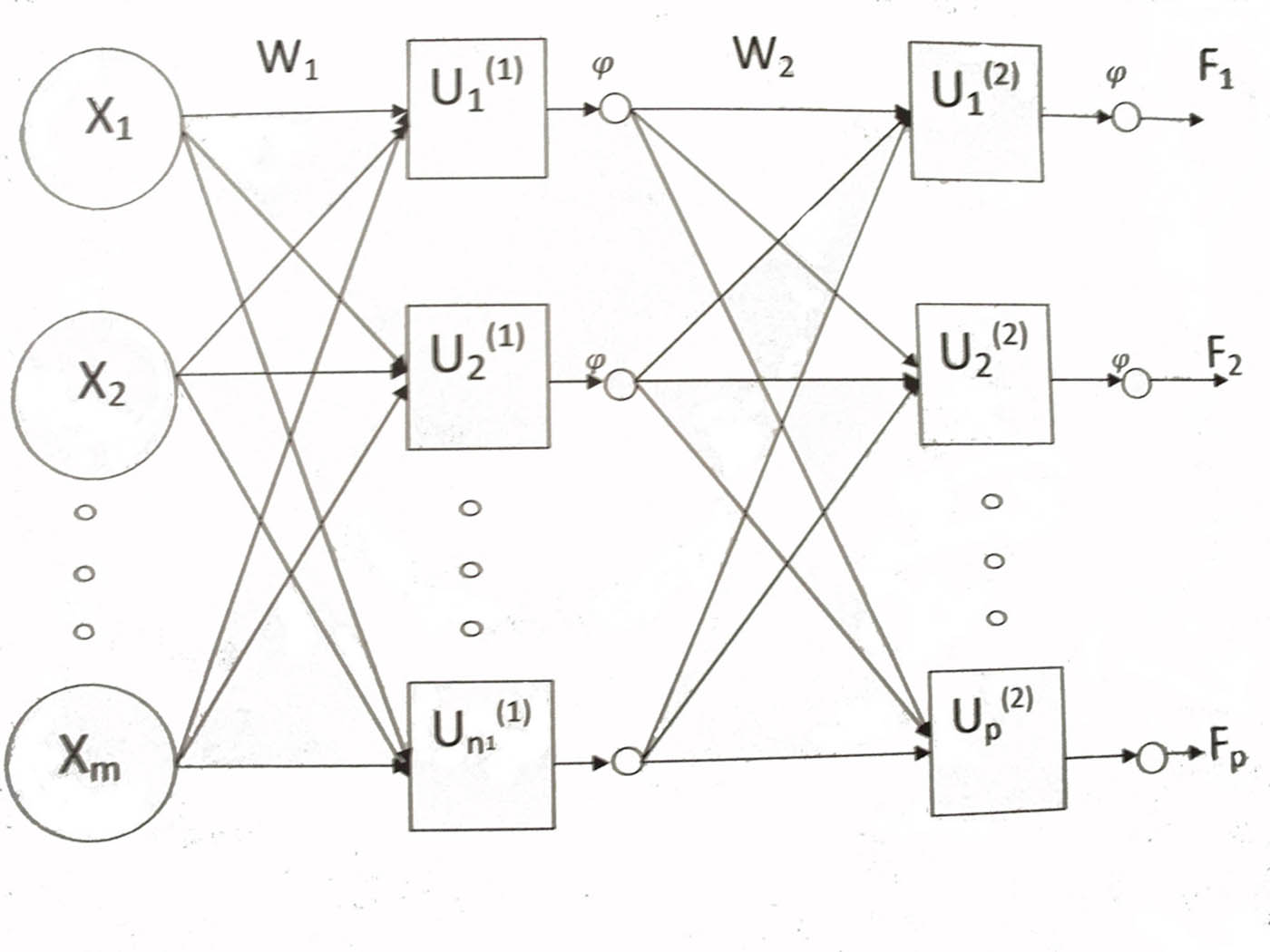 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 19:18:22 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 19:38:57 |
|
||


|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
exp98 - ты молодец что подсказал про регрессии, но давай ближе к делу все-таки. Что такое температура нейросети https://cs.stackexchange.com/questions/79241/what-is-temperature-in-lstm-and-neural-networks-generally Распределение строится так-же как любое распределение по некому сэмплу, например нормализовав гистограмму так чтобы площадь была 1. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 20:17:31 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Прикольный ролик. Мне это напоминает многих водил, желающих сделать разворот через левый пунктир. Так же тупо первая баба тормозит у начала пунктира, остальные также тупо становятся за ней, а потом стой и жди, когда встречка освободится последовательно для каждого из них. Хотя пунктир дальше ещё метров на 10, да и по правилам у тех, что позади, будет помеха справа,а ты - в приоритете. Но в отличии от НС эти водилы не обучаемы. А ещё я видел распределение типа пуассона в натуре, когда ещё не разогнали ресторан-дебаркадер около моста ещё до минобороны. я тогда часто вечером возвращался по набережной из Лужников. И картина повторялась постоянно. До моста стоят тачки, почему-то в основном чёрные. Дебаркадер после моста. Чем ближе к мосту, тем тачки плотнее, затем в 2 ряда, потом в 3 ряда. За рестораном рядность и плотность быстро спадали. Повторялось из года в год. Видимо энтропия всё-таки убывает. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 20:25:58 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
privateРаспределение строится так-же как любое распределение по некому сэмплу, например нормализовав гистограмму так чтобы площадь была 1.Правильно наверное сказали в умном месте, что вместо 1 числа получишь нечто в стиле нечётких значений. И что с того? Постановка задачи есть грамотная? И всё же, что за универ такой? ЛГУ знаю, МГУ знаю, НГУ, даже МГТУ знаю, ОГУ, ТГУ ... тоже знаю. Универ? Не слышал. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 20:34:00 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
private, забыл добавить, что мгновенный срез (из 1000 точек) ты можешь назвать хоть и распределением. Будет ли оно стационарным, чтобы им пользоваться? Гипотезы надо уметь проверять. Статистика. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 20:37:55 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Зачем ему быть стационарным? Оно будет считаться заново в каждой точке прогноза. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 20:54:19 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
privateНикто не вкурсе - как-то можно сделать чтобы нейросеть выдавала распределение для прогноза? Нейросеть обычно выдает одно число, но хотелось бы получить не одно число а распределение, это как-то можно сделать ? Можно попробовать ансамбль сетей, возможно, разной архитектуры: обученные на одинаковых данных, они дадут разные значения (если не переучить). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 22.05.2019, 21:24:21 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
privateавторпропущено... прогноз собственно и тестят на исторических данных берут начальный кусок - строят модель и оценивают как сходятся продолжение данных и прогноз из модели Это понятно - я же написал - мы прогоним по историческим данным и получим некое число - ошибку прогноза. Проблема в том что мы не можем как "эксперт" оценить его. ...у всех получается, а у вас нет... если не можешь оценить как эксперт, т.е. не понимаешь процесса, то и апроксимация у тебя будет - г.... Можно конечно из пушки по воробьям нейросети, но там тоже нужно понимание где что лажает Нейросети это хайп, и лезущее туда замотивированное необразованное большинство вообще не представляет с чем имеет дело. Тынц по матану к этому делу. Если лень читать ищем "теорема Колмогорова", ключевое "возможно" поностью около неё прыгает. privateРаспределение строится так-же как любое распределение по некому сэмплу, например нормализовав гистограмму так чтобы площадь была 1.Оно так не строится, а задаётся, например, для моделирования, если нет аналитического представления - называется "интегральный метод" ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 00:06:31 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Подытожим: 1 Классика - представить числовой ряд как композицию неких функций. Я так понял это не работает, функция слишком сложная, а даже если и работает то нужно вручную проверять и подбирать параметры, загрузить туда ТОП500 чтобы все автоматом получилось скорей всего не удастся. Не подходит. 2 Классика - представить числовой ряд в виде рекурсии, непараметрическая регрессия, имеет еще романтическое название "ядерное сглаживание". Судя по всему хороший вариант, можно представить цифровой ряд в компактной хоть и рекурсивной форме. И можно получить распределение (не понял пока как именно, но примеры есть). 3 Монте Карло на Цепях Маркова - MCMC, тоже вроде работает, по идее тоже можно получить компактное представление - в виде весов цепи. Можно получить распределение. 4 Нейросети - универсальны. Напрямую распределение на них получить нельзя, но вроде-как таки можно если специально добавить кусок который будет заниматься именно прогнозом вероятностей. Проблемы - LSTM работают плохо, поскольку требуют больших мощностей для обучения и сложной правильной настройки, скорей всего нужно будет экспериментировать с обычными CNN. Минус - нет компактного представления. 5 Вейвлеты - по идее это разновидность 1 подхода, представить числовой ряд как композицию вейвлетов. Но что-то по ним маловато движухи последнее время. Также непонятно как на них считать распределение. Итого осталось: непараметрическая регрессия, цепи маркова и нейросети. Далее - хорошо-бы иметь возможность учитывать внешние факторы, как например процентную ставку. Для нейросети она добавляется естественным образом, в регрессию судя по всему тоже ее можно добавить в виде дополнительных слагаемых, с цепи маркова пока непонятно но вроде тоже это как-то можно добавить. авторОно так не строится, а задаётся, например, для моделирования, если нет аналитического представления - называется "интегральный метод" Наверно так, но мне не нужно аналитическое представление. Оно будет эмпирическое в виде нормализованной гистограммы, его можно будет нарисовать чтобы оценить визуально, и использовать для генерации случайной выборки, мне этого достаточно, получать распределение в каком-то аналитическом виде не нужно. Мне и нужно только для моделирования что такое интегральный метод - как я себе это представляю - на гистограмме мы считаем ширину столбца и считаем его площадь. Затем суммируем все столбцы и нормализуем их высоту так чтобы в сумме была единица. П.С. Зачем нужно распределение - чтобы просчитать все возможные варианты и оценить риски. Прогноз - первый шаг, затем нужно еще посмотреть что именно надо делать с этим прогнозом - посмотреть какие варианты есть что получается, какие могут быт убытки в наихудшем случае и выбрать оптимальное действие. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 08:36:19 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
private, всё намешали Монте Карло - это методы моделирования, которые позволяют оценить распределение какой-то "сложной" функции f(x1,x2,...) от независимых параметров 4-е это упрощение 1-го, обычно берётся векторное произведение 2-е куда-то к фракталам уходит - хз как его применять на реальности т.е. ваш алгоритм построить апроксимацию от ряда параметров f(x1,x2,...), т.е. построить чёрный ящик, чем вы это будете делать - 1| 2 | 4| 5 оценить распределение f(x1,x2,...) , моделируя входные параметры, - это М-К теперь вопрос, каким образом исходя из вышеизложженного можно сделать нижеописанное? privateЗачем нужно распределение - чтобы просчитать все возможные варианты и оценить риски. Прогноз - первый шаг, затем нужно еще посмотреть что именно надо делать с этим прогнозом - посмотреть какие варианты есть что получается, какие могут быт убытки в наихудшем случае и выбрать оптимальное действие. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 09:04:18 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
private5 Вейвлеты - по идее это разновидность 1 подхода, представить числовой ряд как композицию вейвлетов. Но что-то по ним маловато движухи последнее время. Также непонятно как на них считать распределение. Слабак. Какая тебе нужна движуха? Анализ не любит суеты. Сиди себе и анализируй. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 09:23:51 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
автороценить распределение f(x1,x2,...) , моделируя входные параметры, - это М-К Нет, будет следующее. Делаем прогноз для Микрософта, у нас есть цена на сегодня - 100$, мы прогоняем Монте-Карло на завтра, и получаем следующее распределение, где всего один параметр - цена. Функция распределения задана эмпирически и имеет следущий вид (если на вход функции подать цен в указанном диапазоне - функция вернет значение по стрелке) Код: javascript 1. Теперь, нам нужно определить - стоит покупать акцию или нет, мы берем эмпирическое распределение цены Микрософт на завтра - генерируем по нему сэмпл на 100 значений, и делаем 100 раз расчет прибыли - затем суммируем все - и смотрим если сумма больше нуля - покупаем, если меньше - не покупаем. (вообще мы можем принять решение даже без распределения, я привел этот способ использования распределения просто как пример, реальный расчет будет сложнее и там будут нужны вероятности, но сама идея та-же). ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 10:00:18 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
vikkiv ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 10:21:52 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
privateЗачем нужно распределение - чтобы просчитать все возможные варианты и оценить риски. Тебе-ж говорено - нереально. Хотя бабло твоё, тебе его и просирать. Все возможные варианты включают диапазон от падения на 50% до роста на 50%. Вот и считай риски. А наиболее вероятный вариант, это размазанный диапазон, в сравнении с которым простейший тренд даёт лучший прогноз. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 12:44:33 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Можно трейдера посадить и платить ему. Пускай предсказывает. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 12:57:08 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
У Intel кстати целые линейки под такие расчёты есть, на любой вкус скалярные (xeon/платинум) векторные: (Xe), матричные: {Nervana, Movidus , Mobileye} и т.д. {Stratix, AgileX, Arria'10} .. не говоря уже о со-процессорах для DataScience под PCIe слоты на 60 ядер Xeon Phi Coprocessor 5110P Вот к примеру под NN http://software.intel.com/en-us/movidius-ncs http://www.intel.ai/nervana-nnp/ ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 20:40:20 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
у нас на R много расчётов (решили что пока встроенного Machine Learning Services хватает в SQL Server 2017/2019) так использование оптимизированных под Intel MKL библиотек ускорило производительность в 20 раз, вместе с переписыванием кода под RevoScaleR функции - сняло кучу проблем и граблей, даже теперь со Spark/DataBricks не приходится заморачиваться (отказались) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 23.05.2019, 20:46:01 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
авторавторЗачем нужно распределение - чтобы просчитать все возможные варианты и оценить риски. Тебе-ж говорено - нереально. Хотя бабло твоё, тебе его и просирать. Все возможные варианты включают диапазон от падения на 50% до роста на 50%. Вот и считай риски. А наиболее вероятный вариант, это размазанный диапазон, в сравнении с которым простейший тренд даёт лучший прогноз. Ты ошибаешься. Целый раздел трейдинга - опционы - основан именно на оценке будущей волатильности. Плюс - есть классические регрессионные модели которые считают это распределение в том или ином виде. Неясно точно как именно ее считать на нейросетях, но там тоже есть варианты. В интернете куча таких графиков  автортак использование оптимизированных под Intel MKL библиотек ускорило производительность в 20 раз Интересный подход, буду иметь в виду если нужна будет больше мощности. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.05.2019, 01:54:37 |
|
||

|
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
|
|||
|---|---|---|---|
|
#18+
Фейсбук сделал Пророка https://github.com/facebook/prophet Интересное чтиво как он работает https://peerj.com/preprints/3190.pdf Пока читал обнаружил что оказывается, есть вероятностные языки программирования, и пророк реализован на одном из таких языков Stan Детали про такие языки ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 24.05.2019, 10:17:32 |
|
||

25 сообщений из 76, страница 2 из 4
|
|
Форумы
[новые:0]
/ Программирование
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
Аппроксимация цен на акции, базис функций, фракталы, стохастические дифф-ур, autoencoder
[новые:0]
