Гость

Форумы
[новые:0]
/ C++
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
C++ BigIntegers parallel library
[новые:0]
104 сообщений из 104, показаны все 5 страниц
|
|
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Не могу найти ничего подходящего. Погуглил, есессно. Все библиотеки используют только один процессор. Кроме того, конструкторов типа Код: plaintext 1. 2. 3. 4. 5. 6. - так и не дождался. До умножения и деления, есессно, дело не дошло. :( У меня в компику 8 процессорных ядер у CPU и 1600 ядер у GPU и ничего они в это время не делают. Если кому-нибудь известна библиотека - поделитесь, пожалуйста, ссылкой. *писать самому как-то не очень.. типа изобретать велосипед. :( ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 09:37:19 |
|
||





|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
CUDA ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 11:08:32 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Спасибо за ответ, однако, не совсем понял, при чём здесь CUDA ? CUDA - это технология программирования видеоадаптеров nVidia. Программировать видеоадаптеры я пока не планирую. Ищу обыкновенный класс BigInt. Ну и сложение, умножение.. к нему. Типа: Код: plaintext 1. 2. 3. Сейчас лазию по Интернету... мож кто-нибудь уже написал. Заодно проверил и библиотеку Microsoft BigInteger для C# (numerics.dll). Она тоже одноногая(еле ползает). :( Ну и всякие самописные смотрю.. они в лучшем случае на уровне студенческих лабораторных работ. С большими числами они не работают. *точнее, делают вид, что работают. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 11:47:53 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValСпасибо за ответ, однако, не совсем понял, при чём здесь CUDA ? CUDA - это технология программирования видеоадаптеров nVidia. Программировать видеоадаптеры я пока не планирую. Ищу обыкновенный класс BigInt. CUDA здесь при том, что оно именно это и делает -- параллельные вычисления на, по странному стечению обстоятельств, видеопроцессоре. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 12:45:54 |
|
||


|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValИщу обыкновенный класс BigInt. Ну и сложение, умножение.. к нему. Если бы ты его не искал, а запрограммировал сам, то понял бы что 1) Это быстрее чем искать 2) Сложение и умножение последовательны и, как следствие, не распараллеливаются. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 13:03:19 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovSerValИщу обыкновенный класс BigInt. Ну и сложение, умножение.. к нему. Если бы ты его не искал, а запрограммировал сам, то понял бы что 1) Это быстрее чем искать 2) Сложение и умножение последовательны и, как следствие, не распараллеливаются. Векторов -- параллелятся. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 13:15:58 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Добрый день MasterZiv . Посмотрел я КУДУ. И никакой библиотеки класса типа BigInt и интерфейса к нему не обнаружил. *вероятно, по странному стечению обстоятельств. Не могли бы Вы привести простенький примерчик типа: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. Ну и откуда скачать header и саму библиотеку. Возможно, я просто не нашёл, или чего-то не понимаю. ***** Взглянул на ещё одну библиотеку: http://www.shoup.net/ntl/ .. компилится, но тоже использует только один процессор. ***** ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 13:29:21 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovЕсли бы ты его не искал, а запрограммировал сам, то понял бы что 1) Это быстрее чем искать 2) Сложение и умножение последовательны и, как следствие, не распараллеливаются. Добрый день Дмитрий. 1) Самому написать, к сожалению, не быстрее. 2) сложение и умножение замечательно распараллеливаются. *написать простенький пример на C++- дело 10-15 минут. Впрочем, Вы и сами можете взглянуть: "Introduction to parallel & distributed algorithms" Adding big integers: http://www.toves.org/books/distalg/#3.3 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 13:39:40 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValВпрочем, Вы и сами можете взглянуть: А мне-то зачем? Это же тебе библиотека нужна... Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 13:48:48 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovА мне-то зачем? Это же тебе библиотека нужна... Ну, хотя бы затем, чтобы в следующий раз не писать такое: Dimitry SibiryakovСложение и умножение последовательны и, как следствие, не распараллеливаются.. А то неудобно как-то. *такая библиотека много кому нужна. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 14:01:44 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValНу, хотя бы затем, чтобы в следующий раз не писать такое: Видишь ли, теория, описанная в книгах, несколько отличается от практики. Да, я верю, что распараллеливание арифметики над числами в миллионы бит даёт выйгрышь. Но на тысячах бит накладные расходы на создание и координацию потоков съедают всю прибыль. И чем расписывать все эти тонкости для чайника, проще сказать "сложение не распараллеливается". Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 14:06:26 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal*такая библиотека много кому нужна. :) Это спорное утверждение. Целые большие числа нужны только в криптографии. А там нет таких разрядностей - миллион цифр. Максимум тысячи, и то двоичных разрядов. Касательно торможения при инициализации числа - вполне возможно тормозит не преобразование из строки, а выделение памяти под результат (перевыделение при росте массива). Если эта догадка верна, то распараллеливание вам не поможет :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 14:12:08 |
|
||


|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Anatoly MoskovskyКасательно торможения при инициализации числа - вполне возможно тормозит не преобразование из строки, а выделение памяти под результат Умножение на 10. Фиг знает как они его делают... Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 14:17:01 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal Не могли бы Вы привести простенький примерчик типа: Ты бы лучше объяснил, что же тебе нужно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 14:18:12 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
АнатолийЦелые большие числа нужны только в криптографии. А там нет таких разрядностей - миллион цифр. Анатолий , называть "большими" числа размером меньше миллиона цифр даже как-то неудобно. АнатолийКасательно торможения при инициализации числа - вполне возможно тормозит не преобразование из строки, а выделение памяти под результат (перевыделение при росте массива). Если эта догадка верна, то распараллеливание вам не поможет :) Я посмотрел. Ребятки не умеют параллельно запихивать циферки из строки в массив. Или не хотят? Я как вижу что-нибудь вроде: Код: plaintext 1. 2. 3. 4. Сразу понятно, что дальше ничего приличного не будет. А утверждают, что их библиотеки для больших чисел. Мда... программисты ещё те... ********* MasterZivТы бы лучше объяснил, что же тебе нужно. Я ж говорю - билиотека, которая на самом деле работает, а не делает вид. И есть проект распределённых вычислений PrimeGrid@home , который ищет всякие там числа Мерсена, Вудала.. и прочие простые. И регулярно утверждают, что нашли что-то большое и ценное. А проверить их невозможно. Может врут, а может не очень.. Во: Record prime Fermat divisor: 57^22747499+1 Divides F(2747497) Ясное дело, я не такой придурок, чтобы самому эти числа искать(кому они нужны), но проверить хочется. *это для начала. есть и другая нужда. :) ****** Сейчас прикинул мож и правда самому натяпать? Ребятки, такая структура подойдёт: Код: plaintext 1. 2. 3. 4. 5. 6. 7. *Ну, ещё операторов натяпать и можно пробовать чё-нибудь сложить. ****** ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 15:09:52 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValИ есть проект распределённых вычислений PrimeGrid@home , который ищет всякие там числа Мерсена, Вудала.. и прочие простые. И регулярно утверждают, что нашли что-то большое и ценное. А проверить их невозможно. Может врут, а может не очень.. Я сначала надеялся что это распараллеливание для чего-то действительно полезного нужно. Но судя по всему оно вообще не нужно. Никому. И вам в том числе. Так что удачи в мечтаниях . ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 15:39:46 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValMasterZivТы бы лучше объяснил, что же тебе нужно. Я ж говорю - билиотека, которая на самом деле работает, а не делает вид. В общем, я понял (далеко не сразу), что ему нужно. Ему нужна библиотека для поддержки вычислений очень больших точных чисел (не с плавающей точкой), которая поддерживала бы распараллеливание вычислений. Если что не так -- поправь. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 15:57:28 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Anatoly Moskovsky , очень приятно, что Вы знаете, кому что нужно и полезно(тем более мне). ... просто удивительно, почему Вы ещё не депутат Государственной Думы. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 15:59:03 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
MasterZiv , Вы совершенно правы. И мне всё равно как она будет считать: параллельно или перпендикулярно. Лишь бы быстро. *пока такой библиотеки нетути. :( ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 16:03:30 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValИ есть проект распределённых вычислений PrimeGrid@home , который ищет всякие там числа Мерсена, Вудала.. и прочие простые. И регулярно утверждают, что нашли что-то большое и ценное. А проверить их невозможно. Может врут, а может не очень.. Во: Record prime Fermat divisor: 57^22747499+1 Divides F(2747497) Ясное дело, я не такой придурок, чтобы самому эти числа искать(кому они нужны), но проверить хочется. А вы что собственно проверить хотите? Что число 57^22747499+1? Как именно? Или что 57^22747499+1 делит F(2747497)? Каким способом? Чтобы проверить, нужен нетривиальный софт. И арифметические операции с большими числами - это только очень маленький его кусочек. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 17:01:32 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
GuestА вы что собственно проверить хотите? Что число 57^22747499+1? Как именно? Чтобы проверить, нужен нетривиальный софт. Для начала, то что число простое. Чего ж тут сложного? К примеру, пишем: Код: plaintext 1. 2. 3. 4. Собственно, нужна только библиотека. А уж всяких алгоритмов достаточно. Начиная от простого решета, до Рабина-Мюллера :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 17:41:30 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal, Рабин-Мюллер не дает гарантию что число простое. А перебрать все возможные делители в ближайший миллиард лет вам никак не успеть, ни на одном процессоре ни на 1000. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 23:17:10 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
?Рабин-Мюллер не дает гарантию что число простое. В качестве проверки можно сгенерить из этого числа RSA ключ. Сработает - точно простое. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 06.09.2013, 23:24:27 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
GuestSerVal, Рабин-Мюллер не дает гарантию что число простое. А перебрать все возможные делители в ближайший миллиард лет вам никак не успеть, ни на одном процессоре ни на 1000. Ясное дело, Мюллер для предварительной проверки перед Лемнером. Но ето ещё рано обсуждать. А насчёт "не успеть".. так моя бабушки считала на калькуляторе "Феликс".. тож говорила, что до конца года не успеть.. У них там цельный отдел ручки крутил. Dimitry SibiryakovВ качестве проверки можно сгенерить из этого числа RSA ключ. Сработает - точно простое. А генератор RSA ключа может генерить ключ из числа с 1 000 000 000 цифрами ? Если может, то за сколько он примерно это сделает? ***************************** Ну да ладно, натяпал пока простенький класс BigInt: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. Ну и конструктор из строки(заполнение вектора). Правда работает чёта медленно. Строку из 1 000 000 000 циферок запихивает в вектор за 180 секунд. :( Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. Посмотрю пока, чегой-то всё так медленно? Ах да, скачал ещё одну библиотеку для больших чисел: C++ Big Integer Library https://mattmccutchen.net/bigint/ Тож одноногая. Однако, надо же что-то для сравнения результатов и времени. *строки больше 10-20 тыс знаков она не переваривает. Подсунул этой библиотеке строку из 100 тыс. цифров.. Уж и в магазин сходил, а у неё всё конструктор хрюкает. Не дождался. :( ****** Всем привет и хорошего настроения. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 12:11:41 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValПосмотрю пока, чегой-то всё так медленно? Или код кривой, или распараллелить забыл. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 13:30:58 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovИли код кривой, или распараллелить забыл. Аха, пожадничал. 128 процессов в вектор пихали.. Переделал. Поставил - не создавать процессов более чем число ядер CPU: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. Exec time : 39.6 seconds. Ща натяпаю каких-нить операторов присваивания, сравнения.. и можно приступать к сумматору, типа A+B=C :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 14:51:38 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Отдельный int на каждую десятичную цифру... Шикарно живёшь, суммирование просядет. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 14:56:20 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValExec time : 39.6 seconds. У меня нет пяти гигабайт ОЗУ, поэтому я ограничился миллионом цифр. Код, абсолютно аналогичный твоему, только без распараллеливания и использования STL, отработал на атомном недобуке за 31мс. Т.е. если бы у меня было ОЗУ, то миллиард цифр был бы всосан за 31 секунду. К чему бы это?.. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 15:27:54 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovОтдельный int на каждую десятичную цифру... Шикарно живёшь, суммирование просядет. Ну, в этом есть некоторое преимущество: сложение и умножение цифр одного разряда никогда не вылезут за пределы int-a. То есть, переполнения можно не ожидать. И есть предположение, что с флагами переноса будет проще. Как надо складывать/умножать/делить я пока не знаю. Зато как решить проблему с недостатком памяти - любой чайник знает. И я тоже. :) *схожу, пожалуй, за колбасятиной, потом чего-нибудь натяпаю. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 15:35:35 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Я дико извиняюсь, но не могу больше ржать, глядя на эти чудеса оптимизации. 1. Вы понимаете, что вот это вообще не работает, т.к нет завершающего нуля? Код: plaintext 1. 2. 2. Если хранить каждую десятичную цифру в отдельном элементе массива, то время парсинга миллиона цифр должно быть не больше нескольких миллисекунд (безо всяких потоков). Откуда там взялись десятки секунд, можно только догадываться. Впрочем долго гадать не придется. atoi на каждую цифру, ОМГ. Вообще-то int digit = str[i] - '0' - вполне достаточно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 15:39:14 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovК чему бы это?.. К тому, что 1 миллиард циферок - это немного больше, чем 1 миллион. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 15:39:59 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValК тому, что 1 миллиард циферок - это немного больше, чем 1 миллион. :) В тысячу раз, да. И что самое забавное - секунда во столько же раз больше миллисекунды. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 16:16:49 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
автор1. Вы понимаете, что вот это вообще не работает, т.к нет завершающего нуля? К сожалению не понимаю. И основная причина непонимания в том, что это работает. :) (конструкторе я пока ничего менять не буду, поскольку натяпываю сумматор). А если Вам не поржать, то Вы могли бы заметить, что никакой проверки строки на корректность - нетути. Так что без получения char-а и его проверки на цифру не обойтись. Это, как сказал бы Рабинович "Раз". В предложенным Вами варианте не просматривается возможность проверки. *конструкции типа int digit = str[i] - '0' - это к доктору или для наладонников и наколенников. (не смотря на то, что вроде бы как работает). По поводу оптимизации : до неё ещё далеко. Потому как если оптимизировать char-ы - до сложения не дойдёшь. Это "Два" (того-же автора). Перегруженный Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. - тоже имеется(как известно, он выводит циферки и буковки на экран). Так вот, циферки на экране просто замечательные. И, по совершенно невероятной причине, именно те что надо! Впрочем, думаю, к вечеру натяпаю простенький сумматор - выложу скрин с короткими цифрами. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 16:28:31 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry Sibiryakov , я ведь написал, что конструктор работает медленнно . И сравнить его, увы, не с чем. Вот у меня ужо есть библиотека, которая за 40 секунд засасывает миллиард цифр. (складывать она пока не умеет :) ) Я привёл достаточно ссылок на библиотеки. Вам известна хоть какая-то, конструктор которой работает быстрее? (точнее, хоть как-то работает с миллиардом цифр). Кстати, библиотека делается для больших чисел, а не для какого-то жалкого миллиона. *и ваще: "Нам что... шашечки или ехать надо"? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 16:49:09 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValавтор1. Вы понимаете, что вот это вообще не работает, т.к нет завершающего нуля? К сожалению не понимаю. И основная причина непонимания в том, что это работает. :) (конструкторе я пока ничего менять не буду, поскольку натяпываю сумматор). Ну я и не сомневался в этом (и в том что вы не понимаете, и в том что скажете что "работает"). Вам следует сначала изучить понятие undefined behavior его последствия, и тогда уже делать выводы работает или нет. А если Вам не поржать, то Вы могли бы заметить, что никакой проверки строки на корректность - нетути. Так что без получения char-а и его проверки на цифру не обойтись. Это, как сказал бы Рабинович "Раз". В предложенным Вами варианте не просматривается возможность проверки. *конструкции типа int digit = str[i] - '0' - это к доктору или для наладонников и наколенников. (не смотря на то, что вроде бы как работает). Можно подумать atoi дает вам возможность проверки :) Притом, что мой вариант как раз дает такую возможность: if (digit < 0 || digit > 9) ... Ладно, я тут не хотел надолго отвлекать вас, желаю вам удачи и до конца жизни сопровождать этот код. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 16:55:45 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Я тут подумал, что слишком жестоко было бы сопровождать такой код до конца жизни. Поэтому вот вам объяснение почему atoi(&ch) - не работает. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 17:08:00 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Anatoly MoskovskyНу я и не сомневался в этом (и в том что вы не понимаете, и в том что скажете что "работает"). Любезный Анатолий, уж не полагаете ли Вы, что приведённые мной циферки я натяпываю ручками? *типа, чтобы ввести народ в заблуждение? Честно-пречестно говорю, что это не я, а программа! Это всё она так выводит на экран, а я только копирую и вставляю сюда. Почему она подлая работает и правильно выводит циферки дело тёмное. :) Ну и есть небольшая разница между моим и Вашим кодом: мой код - вот он - каждый может посмотреть и покритиковать. А Ваш код - он как мёд - вроде бы он есть, а вроде бы его уже и нет... К сожалению, и приведённые Вами функции fn1 и fn2 в программе использовать не удалось. :( хотя написали Вы намного больше, чем натяпанная мной atoi. Надо признаться, я вообще не понял, к какому месту приграммы относятся эти функции. Вроде бы конструктор не должен ничего выводить на экран... Однако ж спасибо за пожелание удачи. *на курсы Ликбеза я обязательно пойду. Скорее всего, после того, как доделаю библиотеку. и сопровождать код мне не придётся, потому как делаю для себя. :) ***** Ах да, выражение int digit = str[i] - '0' довело меня до когнитивного диссонанса. :) ***** И видеоадаптер чёта моргает и драйвер падает когда я в него массив засовываю. Не хочет суммировать... Ща ещё погляжу. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 18:05:14 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValЯ привёл достаточно ссылок на библиотеки. Вам известна хоть какая-то, конструктор которой работает быстрее? У той, которую я написал за пять минут конструктор работает быстрее. Без распараллеливания. И единственная причина почему она не работает на миллиарде цифр - отсутствие пяти гигабайт виртуальной памяти. Если её скомпилировать на 64-х битах - будет работать и на миллиарде. По прежнему быстрее вашей. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 18:23:09 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValПочему она подлая работает и правильно выводит циферки дело тёмное. :) Так ничего удивительного: http://lurkmore.to/Индусский_код ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 19:20:28 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry Sibiryakov , приветствую в Вашем лице всё прогрессивное человечество. Dimitry SibiryakovУ той, которую я написал за пять минут конструктор работает быстрее. Без распараллеливания. Замечательно! Вот где наши Российские таланты! Библиотек, правда, нетути...а талантов у нас огого!. Похоже библиотеки в закромах Родины.. "Если завтра война, если завтра в поход..." вот тогда мы покажем кузькину мать..:) Dimitry SibiryakovИ единственная причина почему она не работает на миллиарде цифр - отсутствие пяти гигабайт виртуальной памяти. Если её скомпилировать на 64-х битах - будет работать и на миллиарде. По прежнему быстрее вашей. Ну да, ну да.. почему пушки не стреляли ?.. "Во первых не было патронов...".. Мда, Дмитрий, Вы тоже вводите меня в ступор. Не работающая библиотека, которая работает быстрее моей. О, как! Как тут не вспомнить классика: "Никогда ж такого не было, и вот опять!..."(с) Виктор Черномырдин. Ну и Ваш код и обладает тем же свойством, что и у Московского товарища из Одессы.. никто его не видел, не щупал и сказать о нём нечего. ****** Сумматор без переноса я сделал. Ща проверю на мелких цифрах для CPU и GPU. И таймеры вкрячу. 7654321 и 1234567 Сумма должна быть: 8888888 Ну а потом строки 7654321 и 1234567 раскручу в цикле: Код: plaintext 1. 2. 3. 4. 5. Получатся миллиардные цифры, которые можно будет сложить без переносов и в сумме все цифры будут восьмёрки. Ежели сегодня успею приведу тайминги. :) ****** Фу-ты ну-ты.. память у моих видеоадаптеров только по 1 гигабайту. Похоже, миллиардные слагаемые не влезут. Ладно, напишу про те которые влезут. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 19:58:55 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValПолучатся миллиардные цифры, которые можно будет сложить без переносов Ну да, ну да... А уж как круто было бы складывать нули... SerValЕжели сегодня успею приведу тайминги. :) Заодно приведи параметры компьютера на котором ты это запускаешь. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 07.09.2013, 20:03:07 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Ну вот, можно проверить сложение с использованием всех имеющихся процессоров. :) Компик вот такой: ************* Процессор: i3820@4.2HGz Материнская плата: ASUS P9X79 WS RAM 64 GB Сопроцессор1: NVIDIA GeForce GTX 460 Сопроцессор2: ATI Radeon HD 5800 Series ************* Сложение на CPU(на одном ядре): Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. Сложение на GPU: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. Закатал в строки Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. - штоб числа были по 100 миллионов цифр. Занимают в акселераторе 765 MBytes памяти. больше не лезет. Результат: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. Хм.. результат как бы заставляет задуматься. :( Ща посмотрю в чём дело. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.09.2013, 14:16:45 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Размеры чисел уменьшил до 10 миллионов цифр и переделал умножение на GPU: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. Результат уже лучше: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.09.2013, 20:03:56 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
На cpu в одном потоке. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. Intel Pentium CPU G2020 2.9GHz ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 09:10:54 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal, а переносы между разрядами при сложении вы что вообще не учитываете? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 13:24:54 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal, а какие задачи ты решаешь? Криптография? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 17:50:52 |
|
||


|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
m_SlaНа cpu в одном потоке.... Exec time : 0.037000 seconds. Поздравляю! ... как известно,быстрее всего работает код, которого о5 же никто не видел. :) Вот отсюда http://www.cs.sunysb.edu/~skiena/392/programs/bignum.c можно скопипастить исходник сложения/вычитания...итд прям вместе с main() ...мож оно ещё быстрее будет. Однако ж не совсем понятно, что Вы хотели сказать. Что одно ядро работает быстрее нескольких? Сколько времени занимает у Вас параллельное сложение пока не видно.. ... видимо оно прячется за многозначительным "Press any key to continue.". Ждём "continue". :) Или, давайте 10000 раз сложим числа размером в 10 000 000 цифр ? Нуачё - вот мой код - складывает одни и те же цифры 10 000 раз: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. Вот результат(CPU одно сложение, GPU 10 тыс): Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. *на акселераторе NVIDIA GeForce GTX 460 время такое же. maytonSerVal, а какие задачи ты решаешь? Криптография? Не, сам я в криптографии не разбираюсь. Но есть ребятки, которые интересуются криптоанализом шифров Bivium и Trivum. GuestSerVal, а переносы между разрядами при сложении вы что вообще не учитываете? Ага, не учитываю, поскольку ещё не умею, а подсказать некому. :( Однако, сначала надо определиться, какой будет ли выигрыш в производительности. Потому как производительность пока определяется копированием слагаемых в память видеоадаптера и копирование результата обратно в память процессора. :( Читаю теорию. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 20:10:29 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValАга, не учитываю, поскольку ещё не умею, а подсказать некому. :( А как же та книжка, которой ты хвастался на предыдущей странице? Ниасилил?.. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 20:31:42 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dimitry SibiryakovА как же та книжка, которой ты хвастался на предыдущей странице? Ниасилил?.. Аха, пока ниасилил. Книжка шибко вумная. :( .. и не хвастался я совсем. Ясное дело, осиливать надо, не изобретать же велосипед. В ближайшие дни постараюсь осилить и применить. :) ***** Ах да, для GPU типа AMD Fusion или Intel HD Graphics использующих shared memory всё будет на порядок быстрее, поскольку реального копирования массивов в память ускорителя не будет(Zero Copy). *у меня такой графики нетути, поэтому попробовать не могу. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 20:39:11 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValDimitry SibiryakovА как же та книжка, которой ты хвастался на предыдущей странице? Ниасилил?.. Аха, пока ниасилил. Книжка шибко вумная. :( .. и не хвастался я совсем. Ясное дело, осиливать надо, не изобретать же велосипед. В ближайшие дни постараюсь осилить и применить. :) ***** Ах да, для GPU типа AMD Fusion или Intel HD Graphics использующих shared memory всё будет на порядок быстрее, поскольку реального копирования массивов в память ускорителя не будет(Zero Copy). *у меня такой графики нетути, поэтому попробовать не могу. Bandwidth памяти RAM-GPU = 100-300 GByte/sec, а PCI-E gen2 16x = 8 GBytes/sec. Вы уверены, что RAM-GPU у вас слабое звено? Или у вас данные в ядрах GPU окажутся в обход шины PCI-E? ;) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 21:45:24 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
в ядрах GPU в обход шины PCI-EBandwidth памяти RAM-GPU = 100-300 GByte/sec, а PCI-E gen2 16x = 8 GBytes/sec. Вы уверены, что RAM-GPU у вас слабое звено? Или у вас данные в ядрах GPU окажутся в обход шины PCI-E? ;) Для AMD Fusion или Intel HD Graphics - копирования массивов не будет: http://social.msdn.microsoft.com/Forums/vstudio/en-US/6426345c-9110-4e58-9f18-a6320b5f75ad/amp-and-zero-copy . ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 09.09.2013, 22:03:42 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValm_SlaНа cpu в одном потоке.... Exec time : 0.037000 seconds. Поздравляю! ... как известно,быстрее всего работает код, которого о5 же никто не видел. :) Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. У Вас сложение на CPU по быстродействию примерно равно сложению на GPU. При этом сложение на CPU можно еще оптимизировать, например SSE прикрутить. Какой смысл в GPU и многопоточности? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 05:50:32 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Вот результаты с использованием gmp 5.1.2 Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 06:21:45 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Добрый день, m_Sla . Про n1.add(n2) - какое ж это сложение? Это не "А= В+С", а реализация оператора "+=". -> A += B - теряется одно из слагаемых - оно становится результатом. ...это как говорят в Одессе - две большие разницы. :) У меня числа складаваются и результат присваивается третьему числу: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133. 134. 135. 136. ================== CPU: A = add(B,C) Exec time : 0.003000 seconds. ================== Теряется ли в gmp 5.1.2 одно из слагаемых - не знаю. Однако, охотно верю. ****** То что последовательное сложение у меня сделано криворуко - согласен. Можно переписать получше. И оптимизировать его можно. Только зачем? Как Вы показали, всё оптимизировано до нас в доступных библиотеках. m_SlaКакой смысл в GPU и многопоточности? Похоже, уже на числах в 100 миллионами цифр, параллельное сложение обгоняет сложение на одном ядре. Вот: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. *Тем не менее, сделаю сложение на CPU векторами, или попробую прикрутить gmp 5.1.2(для сравнения). Всем привет и хорошего настроения. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 14:28:14 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValGuestSerVal, а переносы между разрядами при сложении вы что вообще не учитываете? Ага, не учитываю, поскольку ещё не умею, а подсказать некому. :( Однако, сначала надо определиться, какой будет ли выигрыш в производительности. Угу, складываете вы параллельно к примеру 555....5555 и 444....4445. И у вас возник перенос в последнем разряде. Что толку от параллельного сложения циферок, если потом этот перенос надо будет последовательно по всем разрядам тащить? С умножением будет не лучше. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:13:55 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
?Что толку от параллельного сложения циферок, если потом этот перенос надо будет последовательно по всем разрядам тащить? С умножением будет не лучше. Ш-ш-ш-ш, не спойлери. Дай ему пройти по всем граблям, иначе образовательного эффекта не будет. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:23:03 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValmaytonSerVal, а какие задачи ты решаешь? Криптография? Не, сам я в криптографии не разбираюсь. Но есть ребятки, которые интересуются криптоанализом шифров Bivium и Trivum. Чел, ну насколько я знаю, крипто-библиотеки просто используют MMX/SSE наборы команд чтобы работать с длинной арифметикой. Причём у них длинная арифметика изначально, на уровне постановки ограничена в разрядности. К примеру задались регистром в 512 бит. И работают с такими регистрами. Если там умножение или сложение - то обычно по модулю. Тоесть переноса в самый старший разряд нету. Из этого и танцуют. Юзать для криптографии BigInteger - ну не знаю. Наверное это слишком уж Generic-решение. И что у тебя вообще за операции? На высоком уровне. Разложение на множители? Я к тому что есть разные подходы к оптимизации. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:27:44 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
GuestУгу, складываете вы параллельно к примеру 555....5555 и 444....4445. И у вас возник перенос в последнем разряде. Что толку от параллельного сложения циферок, если потом этот перенос надо будет последовательно по всем разрядам тащить? С умножением будет не лучше. Ну, если бы перенос возникал только в последнем разряде - всё было бы просто: добавить единичку в старший разряд при сложении или остаток от деления на 10 при умножении(при базе=10) :) Однако ж, проблема давно известна, и, разумеется, решена: никто переносы последовательно не тащит. Вот тут "Введение в параллельные и распределённые алгоритмы": описано параллельное сложение больших чисел: http://www.toves.org/books/distalg/#3.3 Однако ж, реализации нетути. То что на аглицком, это ещё ладно. Похоже, там какие-то недоговорённости, не позволяющие ущучить смысл и реализовать на С++. Ну, или у меня недостаточно мозгов(что тоже не исключается). Больше никакой теории найти не могу. На русском - и подавно(всё в закромах Родины). Ежели кто знает как реализовать параллельный сумматор с переносами, прошу поделиться ссылкой(на или алгоритм или реализацию). А то чёта всё застопорилось. :( ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:46:06 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValДобрый день, m_Sla . Про n1.add(n2) - какое ж это сложение? Это не "А= В+С", а реализация оператора "+=". -> A += B - теряется одно из слагаемых - оно становится результатом. ...это как говорят в Одессе - две большие разницы. :) ...У меня почти тоже самое: Код: plaintext 1. 2. 3. 4. 5. 6. 7. Знаю, что не оптимально, но мне переделывать лень. ))) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:48:40 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValстрока1 : 100000000 цифр. строка2 : 100000000 цифр. Конструируем 2 числа: Exec time : 7.85 seconds. ================== CPU: A = add(B,C) Exec time : 17 seconds. У меня больше 100 мс на сложение не получается. Даже миллиард цифр в секунду укладывается. Безо всякой оптимизации. Вот тупо за 5 мин накидал код. Дарю. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143. 144. 145. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 15:54:44 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Добрый день, mayton . maytonЮзать для криптографии BigInteger - ну не знаю. Наверное это слишком уж Generic-решение. И что у тебя вообще за операции? На высоком уровне. Разложение на множители? Я к тому что есть разные подходы к оптимизации. У ребят есть свой программист на зарплате. Он им сейчас на КУДЕ делает. Библиотека нужна мне. Ну, скажем для личных нужд. Никаких денех я за это не получаю, и в обозримом будущем не получу. По работе я ничего не программирую. Я, вообще, не программист. С++ для меня не более, чем удобный калькулятор. (C# тоже годится, но уж больно медленный). Ну вот захотелось мне попроверять кое-что.. у каждого свои тараканы в голове... А числа большие, даже в памяти не помещаются. Вот и пришла мне мысль, что вычисляя параллельно на 1600 процессорах результат можно получить немного быстрее, чем на одном. Началось, как писал выше, с поиска подходящей библиотеки..которой, как оказалась нетути. Точнее, у "Cray MP" она есть.. у меня нетути. *как-то Таг :) *простые числа, разложение на множители.. это тоже. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:16:52 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Ребятки, спасибо за отклики. Я сейчас внимательно всё посмотрю и отвечу. Однако ж и меня к вам вопрос: Вы на самом деле считаете, что вычисления на 1600 процессорах медленнее, чем на одном??? Интересно, как бы вы рассуждали, будь у вас в процессоре хотя бы 1000 ядер? *ладно, ладно.. помнится во времена, когда "процессоры Интел ускоряли Интернет" нам обещали 80 ядер. Ну, хоть 80. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:30:09 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValА числа большие, даже в памяти не помещаются. Вот и пришла мне мысль, что вычисляя параллельно на 1600 процессорах результат можно получить немного быстрее, чем на одном. Началось, как писал выше, с поиска подходящей библиотеки..которой, как оказалась нетути. Точнее, у "Cray MP" она есть.. у меня нетути. *как-то Таг :) *простые числа, разложение на множители.. это тоже. :) Я думаю что это забавный мозговой эксперимент. Сама по себе задача сложения многоразрядных чисел давно вдоль и поперёк изъезжена и ничего здесь поделать нельзя. Яркий пример - деление или нахождение остатка от деления. Операция принципиально несократимая. Ее можно иногда задавать таблично, иногда что-то кешировать но один хрен она - тот самый гранит который грызут все криптоаналитики. По сути она-же защищает наши засекюренные файлы от "жены" и "спецслужб". (подчеркнуть что опаснее !). А если серъезно - то факторизация гораздо интереснее чем то чем ты занят. Поинтересуйся как-нибудь. Можно зацепить краем теорвер, теорию чисел, алгебру. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:36:19 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValъПохоже, там какие-то недоговорённости, не позволяющие ущучить смысл и реализовать на С++ну там отсылка к разделу 3.1 (parallel prefix scan) - это самая сложная часть. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:37:29 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValЕжели кто знает как реализовать параллельный сумматор с переносами, прошу поделиться ссылкой(на или алгоритм или реализацию). А то чёта всё застопорилось. :( http://literaturki.net/elektronika/cifrovaya-shemotehnika1/165-parallelnye-summatory-s-parallelnym-perenosom (шутка) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:42:26 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonЯ думаю что это забавный мозговой эксперимент. Скорее это очень хороший способ прокачать мозг ТСа. Возможно, в результате он дойдёт до уровня, достаточного для того, чтобы раскрыть один маленький секрет длинной арифметики: гораздо эффективнее и проще распараллеливать конечный алгоритм чем элементарные операции. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.09.2013, 16:47:55 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValОднако ж, проблема давно известна, и, разумеется, решена: никто переносы последовательно не тащит. Вот тут "Введение в параллельные и распределённые алгоритмы": описано параллельное сложение больших чисел: http://www.toves.org/books/distalg/#3.3 Однако ж, реализации нетути. То что на аглицком, это ещё ладно. Похоже, там какие-то недоговорённости, не позволяющие ущучить смысл и реализовать на С++. Ну, или у меня недостаточно мозгов(что тоже не исключается). Больше никакой теории найти не могу. На русском - и подавно(всё в закромах Родины). Ежели кто знает как реализовать параллельный сумматор с переносами, прошу поделиться ссылкой(на или алгоритм или реализацию). А то чёта всё застопорилось. :(реализация алгоритма на С в лоб, без всякой оптимизации и без распараллеливания см. void BigInt::parallel_add(BigInt& s): Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. 117. 118. 119. 120. 121. 122. 123. 124. 125. 126. 127. 128. 129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143. 144. 145. 146. 147. 148. 149. 150. 151. 152. 153. 154. 155. 156. 157. 158. 159. 160. 161. 162. 163. 164. 165. 166. 167. 168. 169. 170. 171. 172. 173. 174. 175. 176. 177. 178. 179. 180. 181. 182. 183. 184. 185. 186. 187. 188. 189. 190. 191. 192. 193. 194. 195. 196. 197. 198. 199. 200. 201. 202. 203. 204. 205. 206. 207. 208. 209. 210. 211. 212. 213. 214. 215. 216. 217. 218. 219. 220. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 08:38:50 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
m_Slaреализация алгоритма на С в лоб, без всякой оптимизации и без распараллеливания см. void BigInt::parallel_add(BigInt& s):Дык, там все самое сложное в распараллеливании prefix scan. А вы его циклом сделали, который не распараллеливается. А остальное то элементарно. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 09:28:56 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
?m_Slaреализация алгоритма на С в лоб, без всякой оптимизации и без распараллеливания см. void BigInt::parallel_add(BigInt& s):Дык, там все самое сложное в распараллеливании prefix scan. А вы его циклом сделали, который не распараллеливается. А остальное то элементарно.ну так надо ТСу, а не мне пусть распараллеливает ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 10:15:08 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
2 Anatoly Moskovsky : Посмотрел Ваш подарок. Аппетитный такой подарок, спасибо. *правда, в нём непонятная библиотека boost. Про буст я не знаю. m_Sla , Вы молодец, разобрались. Спасибо. Правда в Вашем коде я пока разобраться не могу. Однако ж сам дошёл до получения вектора <carry>. Получить из <prefix scan> <carries> пока не получается. :( Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Как Вы получаете из <prefix scan> <carries> - ещё непонятнее. Каким-то копированием памяти? ??? Совсем непонятно. Я пробую так: Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. Векторы независимые, чтобы после того как заработает, распараллелить. Тружусь.. Всем привет и хорошего настроения. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 18:02:04 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValправда, в нём непонятная библиотека boost. Про буст я не знаю. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 18:07:12 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonА если серьёзно - то факторизация гораздо интереснее чем то чем ты занят. Поинтересуйся как-нибудь. Можно зацепить краем теорвер, теорию чисел, алгебру. Этим всё равно придётся заняться. Патамушта держать в памяти BigInt-ы (векторы с миллиардом знаков) - это ж никакой памяти не хватит. Только для примеров. Если число долго не используется, может быть есть смысл хранить его в факторизованном виде. Или как-то упакованным. А при необходимости - распаковывать. Но пока об этом рано говорить. Этим можно заняться после базовых операций(сложение, умножение..). Факторизация, в этом случае, тоже должна быть быстрой. Думаю, и тут 1600 процессоров помогут. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 18:17:01 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal, простые числа (prime numbers) не раскладываются на можнители. В этом кстати и соль этой задачи - в поиске подобных чисел. Природа кстати такие задачи обходит и просто не решает. Просто ей не нужна чисельная точность до младшего разряда. Тот-же double или extended можно рассматривать как как biginteger но с экспоненциальной сеткой. Тоесть чем больше число - тем грубее у него абсолютная погрешность. Можно удобно посчитать соотношение поперечника вселенной к диаметру электрона и решить это в double и получить вполне вменяемый с точки зрения физики ответ. В твоих числах для решения этой задачи толку нет. Мы всё равно не можем с точностью до микрометра посчитать поперечник вселенной. Погрешности числителя и знаменателя разные. Улавливаешь? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 18:40:40 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
mayton , простые числа тоже как-то хранят. Типа 2^n+1. Мож и остальные так хранить. Ну а насчёт природы.. ээ.. Неперу про его логарифмы чего только не говорили.. Лет 300 оне без применения лежали. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 19:16:16 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Ты нарисовал формулу похожую на "числа Мерсена". С некоторым отличием там минус 1 а не плюс. Отлично. Но это не все простые числа а лишь ничтожно малая их часть. Кроме того тебе никто не обещал сжатия места после факторизации. Это ты сам неверное придумал? Факторизация она ... для других дел. Я про то что физика, как наука о природе довольствуется расчётами в double. Ей не нужны копейки в младших разрядах. Так-то... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 19:24:46 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValдержать в памяти BigInt-ы (векторы с миллиардом знаков) - это ж никакой памяти не хватит. А я это говорил ещё на первой странице... Да и для целей криптографии (где простые числа в основном и используются) гораздо выгоднее числа держать в двоичном виде, а не двоично-десятичном как у тебя. Работает оно так потом быстрее. Posted via ActualForum NNTP Server 1.5 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 19:29:57 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
mayton , я с Вами полностью согласен. И с Вами, Дмитрий . И зачем библиотеки для больших чисел.. а Микрософт недавно добавила в C#.. :) *хранить в int-ах приходится потому, что у акселераторов пока нет типа char. Делают. и векторы у них есть только короткие, типа rgbi. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 20:14:59 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal, От буйной фантазии юного (ш)кодера нет спасения ни для железа ни для софта и вобщем то голове покоя тоже нет. Я не знаю что там Mircrosoft ввела но кажется в С#/Net decimal существовал давно и его основное назначение - работа с финансовыми расчётами и сопряжение с типами данных в DBMS и конвертация туда и обратно. Я не знаю зачем там тебе так сильно нужна хардкорная оптимизация сложения ну если уж так сильно хочется - почитай про: - BCD арифметику - Учебник Юрова (2 издание) Assembler - Глава 8 - Арифм.операции над двоично-десятичными числами (команды AAA, ADC, AAS, AAM, AAD). P.S. Тут в смежном форуме тоже был один перфекционист. Пилил свою In-memory db с ооочень быстрым откликом. Только вот любое сопряжение с ней из .Net к примеру просаживало отклики тысячекратно. Вот такой вот архитектурный промах-с. Так ште... не ошибись дверью. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 21:13:52 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
mayton , если я Вам так сильно мешаю. не обязательно ведь заглядывать в эту ветку. Не правда ли? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 21:57:14 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Извини брадт. Я всё таки модератор. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 22:09:47 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonИзвини брадт. Я всё таки модератор. Ну и замечательно. В таком случае, не буду утомлять модераторов и остальных участников форума "буйными фантазиями юного шкодера". Всем хорошего настроения. За сим, разрешите откланяться. С уважением, SerVal. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 11.09.2013, 22:29:10 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValПро буст я не знаю. Может оно и к лучшему. Меньше знаешь - крепче спишь. Но не беспокойтесь, это вовсе не благодаря Бусту все работает быстрее в сотни раз :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 12.09.2013, 01:24:48 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerVal m_Sla , Вы молодец, разобрались. Спасибо. Правда в Вашем коде я пока разобраться не могу. Однако ж сам дошёл до получения вектора <carry>. Получить из <prefix scan> <carries> пока не получается. :( Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Как Вы получаете из <prefix scan> <carries> - ещё непонятнее. Каким-то копированием памяти? ??? Совсем непонятно.<prefix scan> сдвигаем вправо на один разряд и получается <carries> 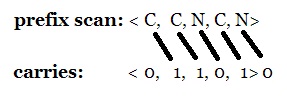 Как распараллелить <prefix scan> написано тут http://www.toves.org/books/distalg/#3.1 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 12.09.2013, 05:29:38 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonА если серъезно - то факторизация гораздо интереснее чем то чем ты занят. Поинтересуйся как-нибудь. Можно зацепить краем теорвер, теорию чисел, алгебру.Да-да. Попробуйте разложить на множители число ну хотя бы с 300 десятичными цифрами. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 12.09.2013, 07:24:03 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
?maytonА если серъезно - то факторизация гораздо интереснее чем то чем ты занят. Поинтересуйся как-нибудь. Можно зацепить краем теорвер, теорию чисел, алгебру.Да-да. Попробуйте разложить на множители число ну хотя бы с 300 десятичными цифрами. При чём здесь 300? Я автору предложил интересное поле для экспериментов. Задача факторизации более интересна и познавательна чем сложение. Я сам не претендую ни на что. Только подсказываю. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 12.09.2013, 19:14:32 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonПри чём здесь 300?Ну просто типичный размер для RSA ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 13.09.2013, 08:08:34 |
|
||

Период между сообщениями больше года.
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Ребятки, я тут маленько сложение доделал. Однако ж результаты не впечатляют. :( D:\aProjects\TestBigInt\x64\Release>TestBigInt.exe -nvidia Accelerator : NVIDIA GeForce GTX 980 ============== BigInt1 размер : 10 миллионов цифр. BigInt2 размер : 10 миллионов цифр. Loop = 100 Addition on CPU: 33.8 seconds. Addition on GPU: 26.8 seconds. ****** При сложении на видеокарте она загружена на 3-5%, а ЦПУ на все 100%. Понятно, что и ускорения как такового нетути. Подозреваю, что это из-за неподходящей структуры BigInt. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. Вектор для хранения удобен, но очень медленно заполняется значениями: resize(), push(), push().. Нельзя ли заполнить вектор из строки параллельно? (чёта никакой идеи по этому поводку нетути). Или изменить сам класс BigInt? *идеи тоже нетути. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 08:45:35 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Понатыкал где только можно #pragma loop(hint_parallel(4)) Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. ... но не помогло. :) ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 09:07:52 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValВектор для хранения удобен, но очень медленно заполняется значениями: resize(), push(), push().. Есть мощный ускоритель -- reserve(). SerValНельзя ли заполнить вектор из строки параллельно? resize(), push(), push( -- это: выделение новой памяти нужного нового размера копирование элементов из старой памяти в новую в пределах минимума из старого и нового размера выполнение конструкторов для элементов (новый размер - старый размер) выполнение деструкторов для элементов (старый размер - новый размер) сам подумай, какие из этих операций можно распараллеливать. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 09:20:55 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Ну и появилась ценная идея: может хранить большие числа в научной нотации? Типа: a*2^n+b; Тогда можно ускорителю передавать не огромные строки, а числа a, n и b. ГПУ всё равно делать нечего, пусть сам в своей памяти и распакует перед сложением. А результат вернёт тоже в научном виде. *правда как распаковывать я тоже не знаю, но где-то ж, наверное, написано? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 09:22:29 |
|
||
|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
MasterZivЕсть мощный ускоритель -- reserve(). - reserve() уже используется (посмотрите код выше). Посмотрю пока как распаковывать научную нотацию в массив int[]. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 09:44:01 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValНу и появилась ценная идея: может хранить большие числа в научной нотации? Типа: a*2^n+b; Тогда можно ускорителю передавать не огромные строки, а числа a, n и b. ГПУ всё равно делать нечего, пусть сам в своей памяти и распакует перед сложением. А результат вернёт тоже в научном виде. Чел. Это просто какой-то фейспалм! Во первых не все числа точно представимы в сабж. Во вторых что значит "ГПУ всё равно делать нечего". Это что ? Откуда? Как так вообще можно делать постановки?! А потом в дайджестах новостей софта и железа стоит плачь и вопль великий... дескыть железо греется без причины.... занято неизвестно чем... Может адварь какой или троян? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 13:07:26 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonSerValНу и появилась ценная идея: может хранить большие числа в научной нотации? Типа: a*2^n+b; Тогда можно ускорителю передавать не огромные строки, а числа a, n и b. Во первых не все числа точно представимы в сабж. Все, только a и b будут иметь порядок максимального sqrt(a*2^n+b) Например для любого x64 числа это а и b размером до 2^32 и n = 32 Только не понимаю зачем строки, когда можно считать массив N байт одним числом из 8N бит. Например 10 байт это числа до 2^80 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 13:25:30 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonЭто просто какой-то фейспалм! Во первых не все числа точно представимы в сабж. Спасибо что сказали. Теперь буду знать. Заодно и не буду тратить время на поиск преобразования таких чисел в массив. Поищу в интернете - нет ли какого другого компактного формата представления больших целых чисел. ***** Для нВидии карт выпустили библиотеку для работы с большими числами. Называется CUMP. Какой-то умный японец сделал. А для С++ AMP такой библиотеки нетути. :( *cобственно говоря мне нужна не столько библиотека, сколько функции типа isDivider(number), isPrime(number).. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 13:46:24 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dima ТВсе, только a и b будут иметь порядок максимального sqrt(a*2^n+b) Например для любого x64 числа это а и b размером до 2^32 и n = 32 a, b, n - от 0 до MAXUINT64. К тому же база может быть и не двойкой, а десяткой или больше. Только не понимаю зачем строки, когда можно считать массив N байт одним числом из 8N бит. Например 10 байт это числа до 2^80 Ну, тогда нужна какая-то библиотека или исходники, чтобы можно было складывать и вычитать числа из 8N бит. У меня такой нетути. К тому же для вычислений на ГПУ библиотеки для ЦПУ не подходят, то есть надо исходник. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 14:01:18 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
SerValУ меня такой нетути. К тому же для вычислений на ГПУ библиотеки для ЦПУ не подходят, то есть надо исходник. GMP посмотри, она с исходниками вроде ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 14:25:38 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dima TSerValУ меня такой нетути. К тому же для вычислений на ГПУ библиотеки для ЦПУ не подходят, то есть надо исходник. GMP посмотри, она с исходниками вроде Кстати ты нашёл где там "gmp.h" ? Я - нет. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 15:51:49 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonКстати ты нашёл где там "gmp.h" ? Я - нет. ЕМНИП Он в процессе сборки либы появляется. В виндовсе сам ниасилил. Мне дали готовую .lib для MSVC2008 с gmp.h в линуксе надо сначала отдельным пакетом установить (libgmp-dev) и при компиляции так Код: plaintext 1. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 16:08:08 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
ОК. У меня MinGW для Windows. Я попробую доустановить пакеты поддержки GMP для начала. Если не выйдет по попрошу у тебя собранную либу. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 16:11:43 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonОК. У меня MinGW для Windows. Я попробую доустановить пакеты поддержки GMP для начала. В дебиан все просто, одна строчка Код: plaintext 1. и пользуйся. maytonЕсли не выйдет по попрошу у тебя собранную либу. Боюсь что не поможет. Она у меня x32 для виндовса. А у тебя x64 ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 16:22:51 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Вроде получилось. Зашёл в GUI inst. manager. Накликал чекбоксов возле *gmp*. Что-то обновилось. Код: plaintext 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Вечером попробую. P.S. Берегись Миллер. И этот чортов раввин.... ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 08.04.2015, 16:29:02 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
maytonКстати ты нашёл где там "gmp.h" ? Я - нет.distclean-hdr: -rm -f config.h stamp-h1 gmp.h: $(top_builddir)/config.status $(srcdir)/gmp-h.in cd $(top_builddir) && $(SHELL) ./config.status $@ ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.04.2015, 06:06:37 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dima TmaytonКстати ты нашёл где там "gmp.h" ? Я - нет. ЕМНИП Он в процессе сборки либы появляется. В виндовсе сам ниасилил. Мне дали готовую .lib для MSVC2008 с gmp.h в линуксе надо сначала отдельным пакетом установить (libgmp-dev) и при компиляции так Код: plaintext 1. Под windows есть mpir - форк от gmp, подпиленный для сборки в VS. ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.04.2015, 06:45:38 |
|
||

|
C++ BigIntegers parallel library
|
|||
|---|---|---|---|
|
#18+
Dima TМне дали готовую .lib для MSVC2008 с gmp.h Бывает иногда встречаешь интересный проект, а *.sln под него нет. В таких случаях первым делом создаю *.sln /и жизнь становится веселей/. PS: Сколько с C++ работаю, а c make не могу подружиться. /но не потому что не понимаю как он работает/. Скорее всего причина в том, что я ленюсь узнать как вести отладку проектов для которых нет *.sln. Кстати может кто подскажет как? ... |
|||
|
:
Нравится:
Не нравится:
|
|||
| 10.04.2015, 08:50:00 |
|
||

104 сообщений из 104, показаны все 5 страниц
|
|
Форумы
[новые:0]
/ C++
[новые:0]
[игнор отключен]
[закрыт для гостей]
/
C++ BigIntegers parallel library
[новые:0]
